1. 技术相关
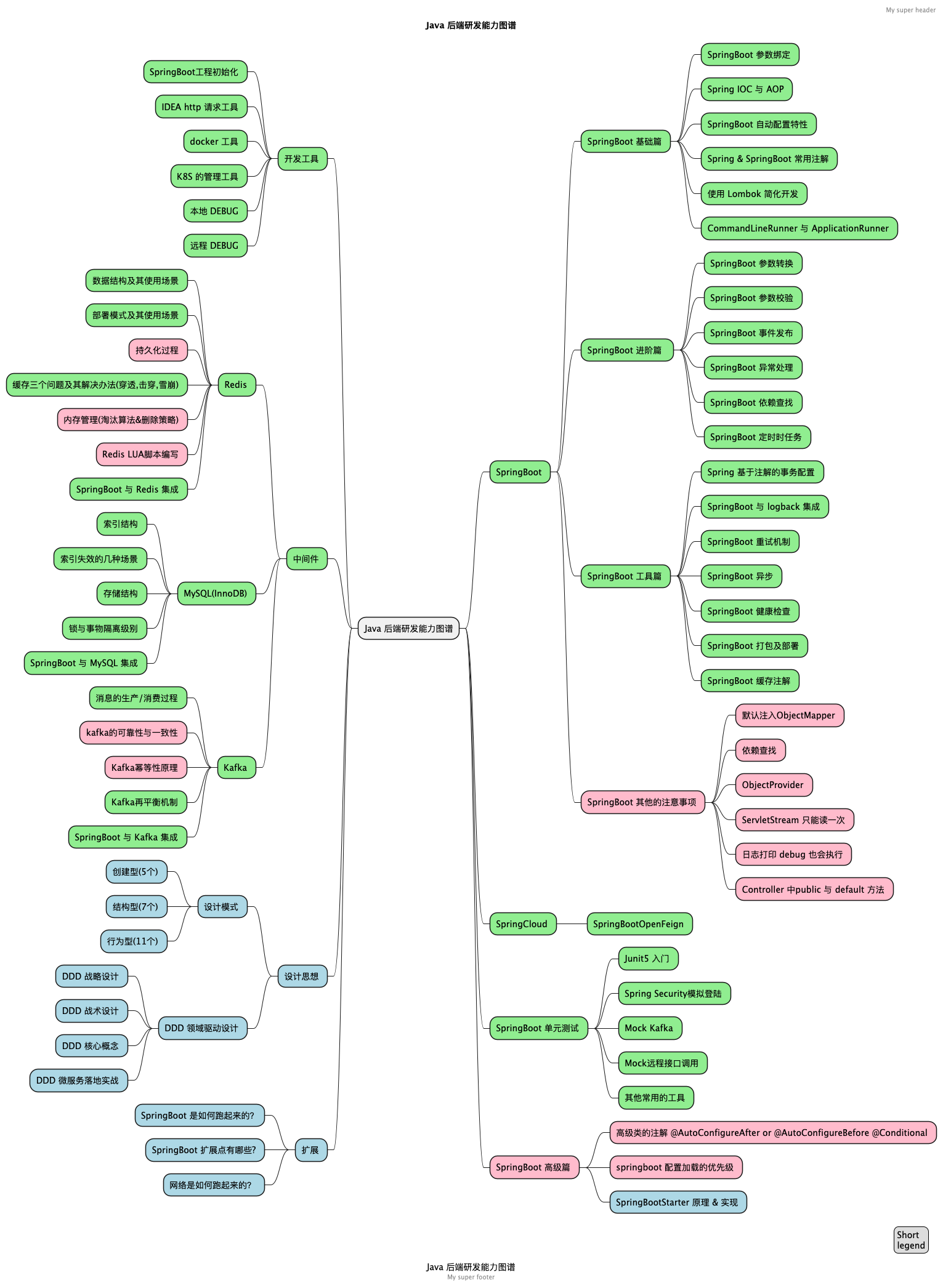
1.1. 能力图谱
1.2. 书籍推荐
《effective java》
《GOF设计模式》
《深入理解java虚拟机》
《代码大全2》
《重构》
《亿级流量网站架构核心技术》
《企业应用架构模式》
《微服务架构设计模式》
2. HTTP
2.1. HTTP 简介
HTTP协议(超文本传输协议HyperText Transfer Protocol),它是基于TCP/IP 通信协议来传递数据的 简单来说就是客户端和服务端进行数据传输的一种规则。
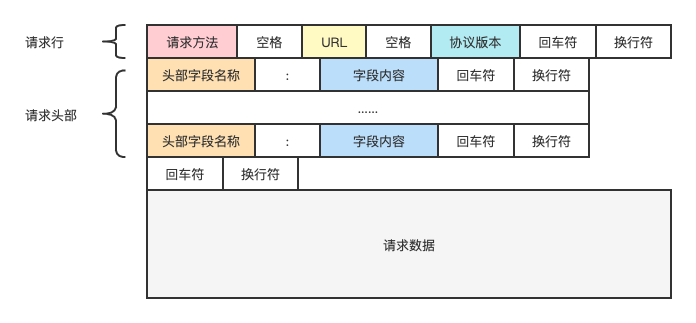
2.2. HTTP 请求体
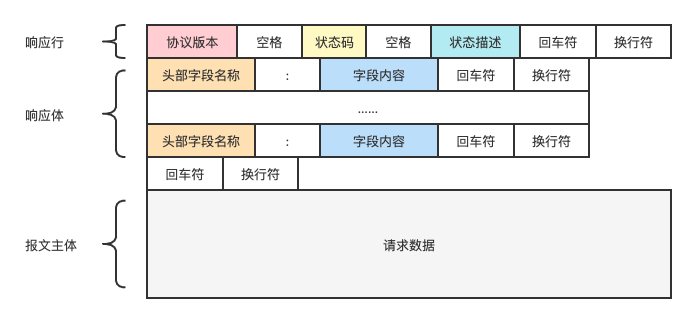
2.3. HTTP 返回体
2.4. Chrome 浏览器查看请求
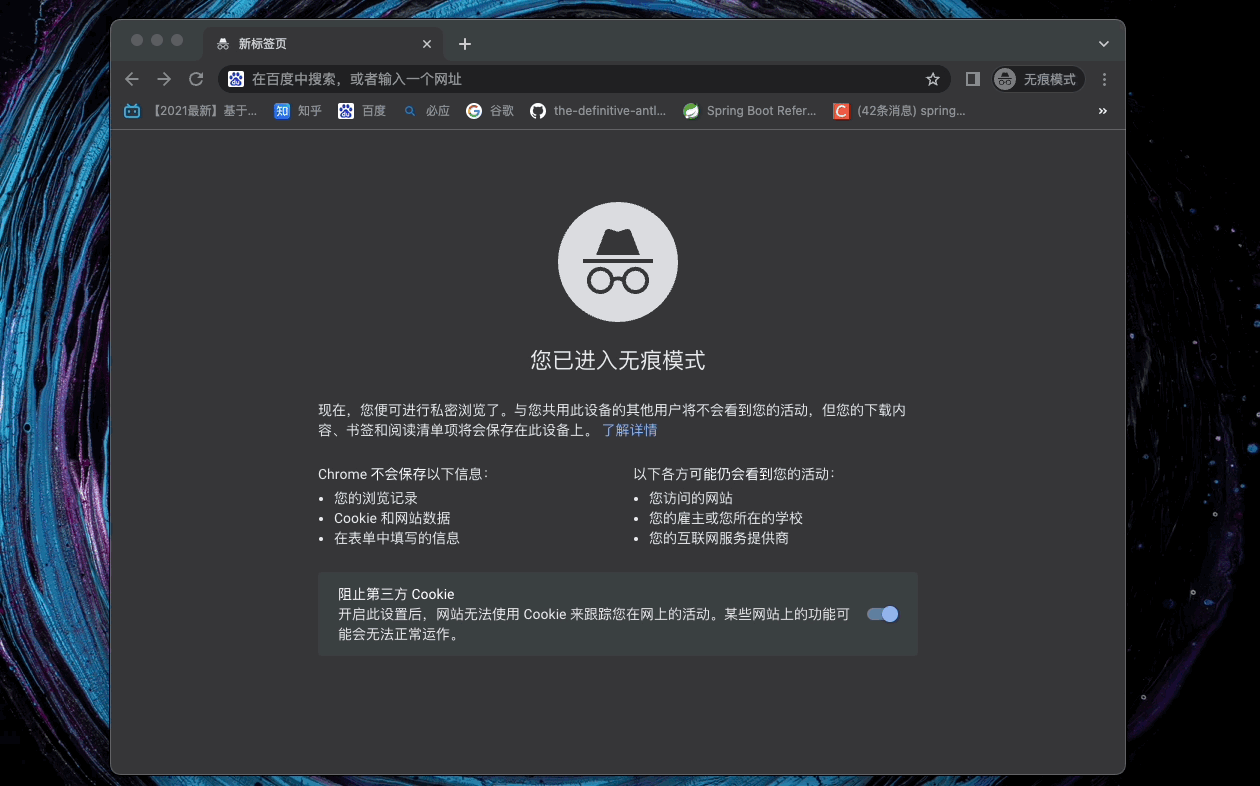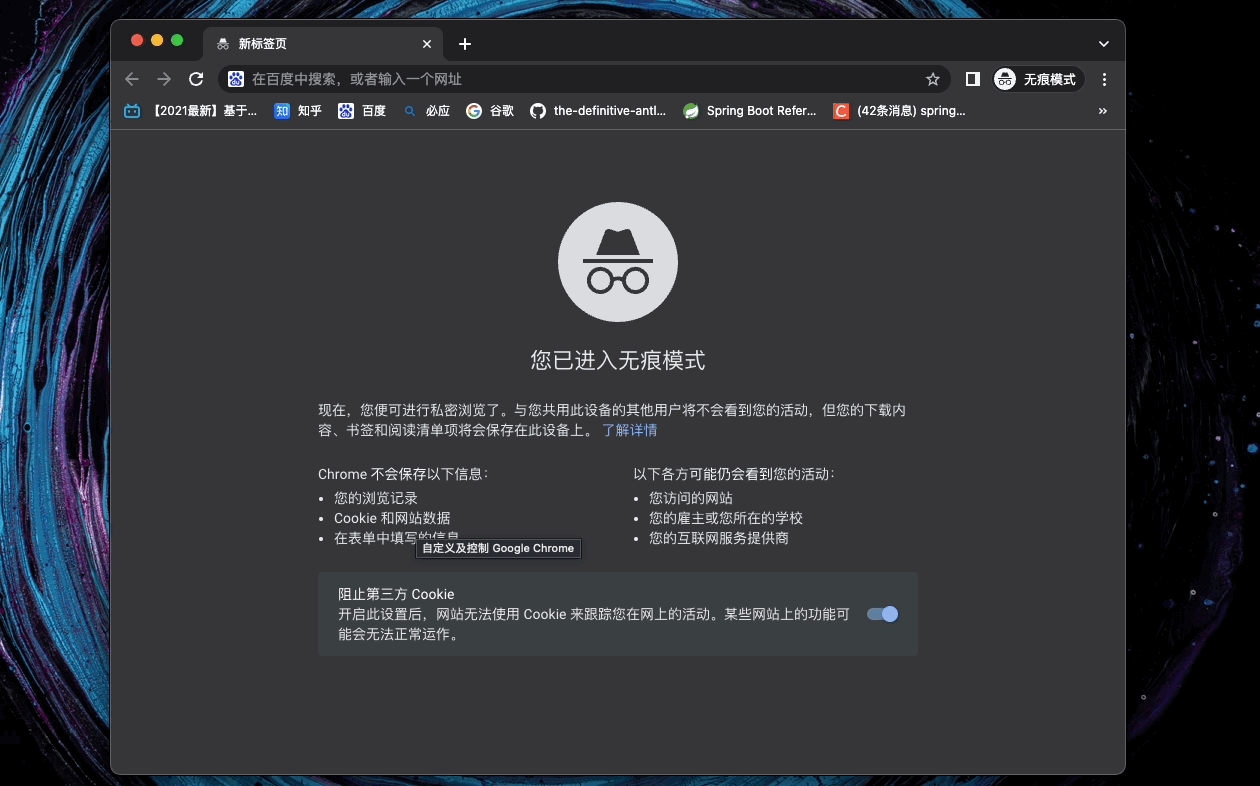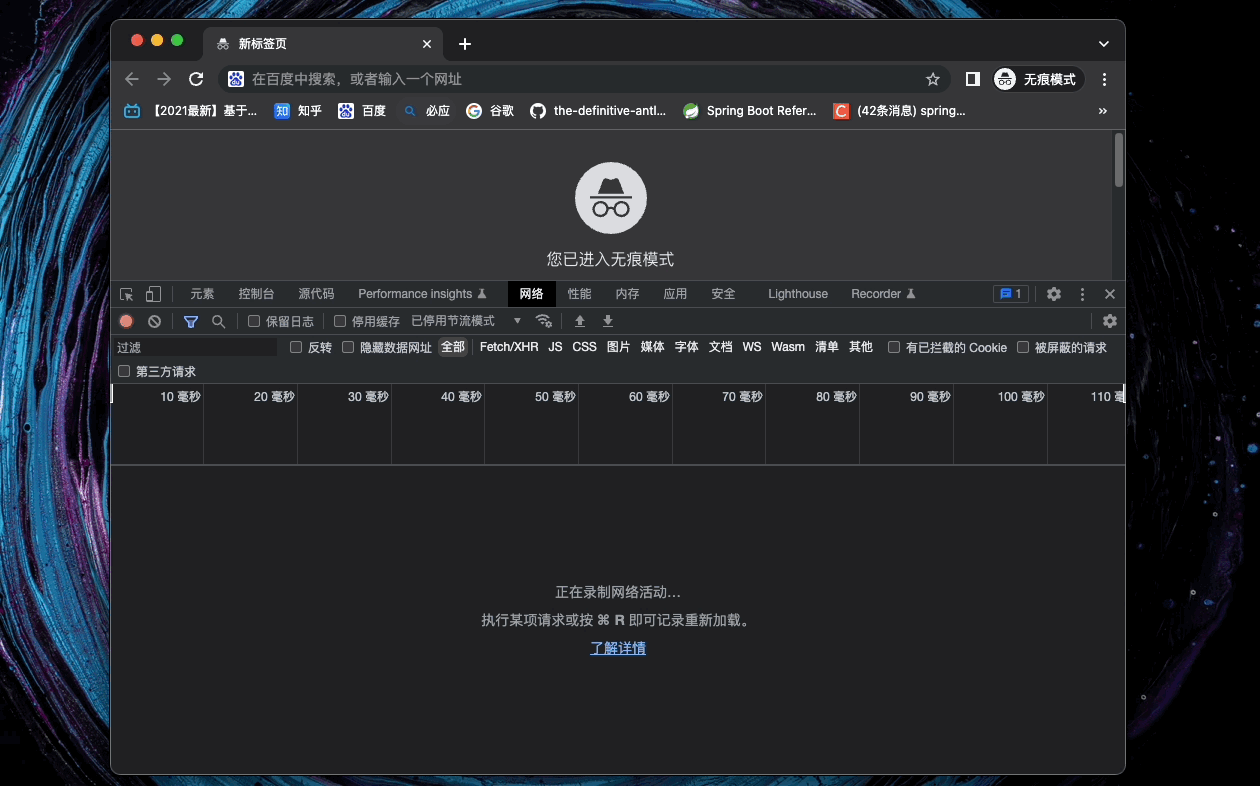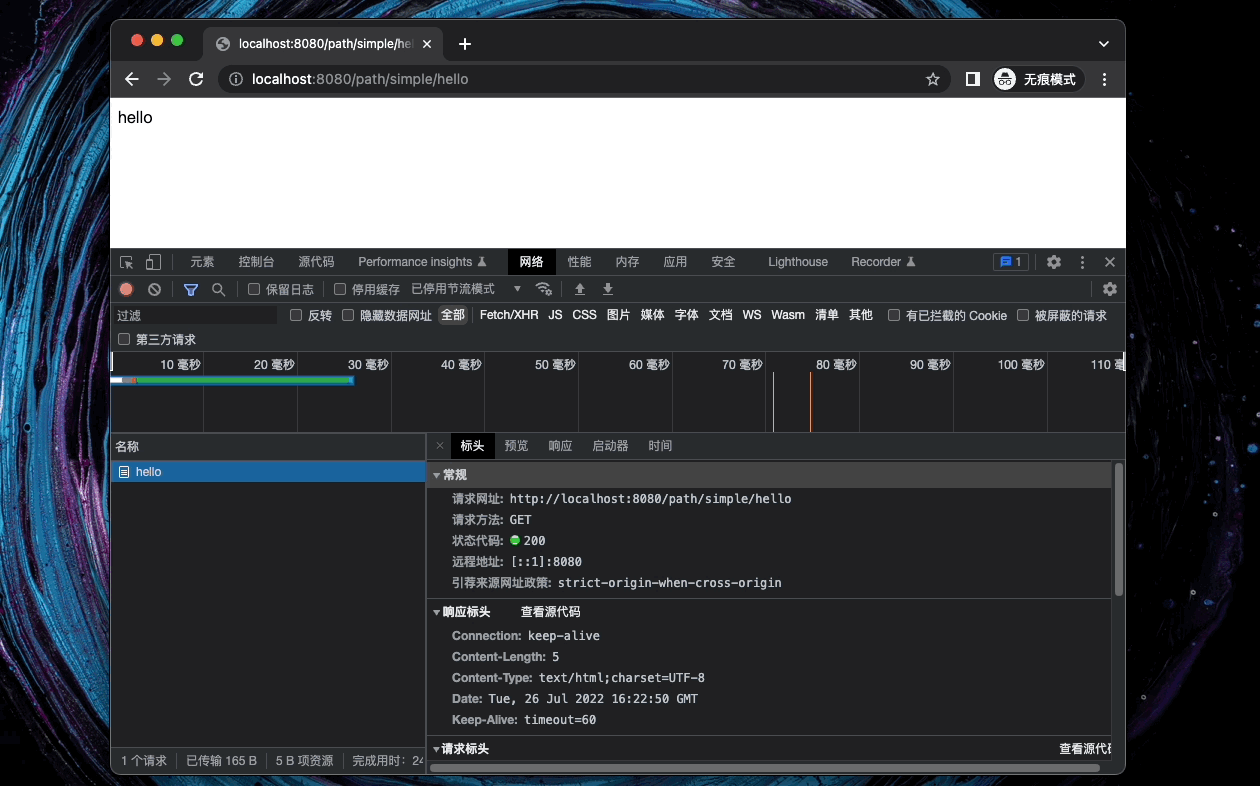
2.5. 命令行发出 HTTP 请求
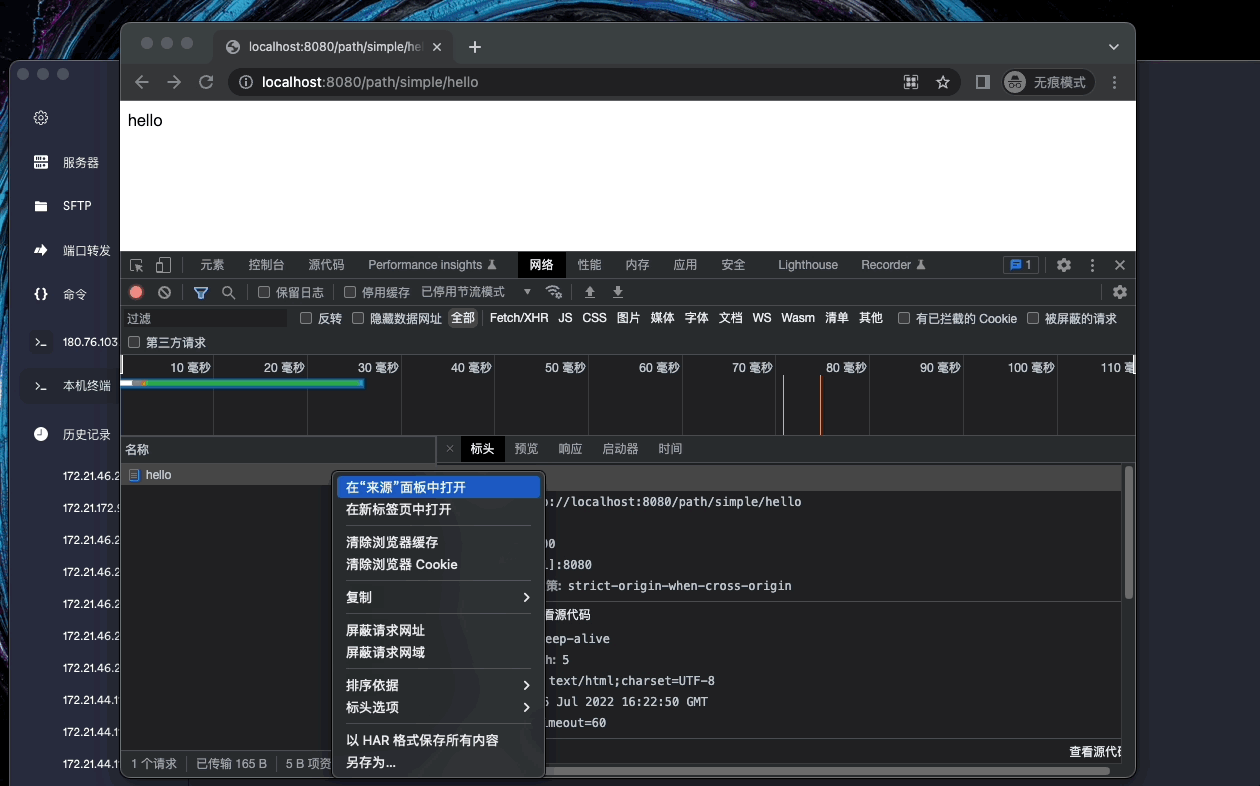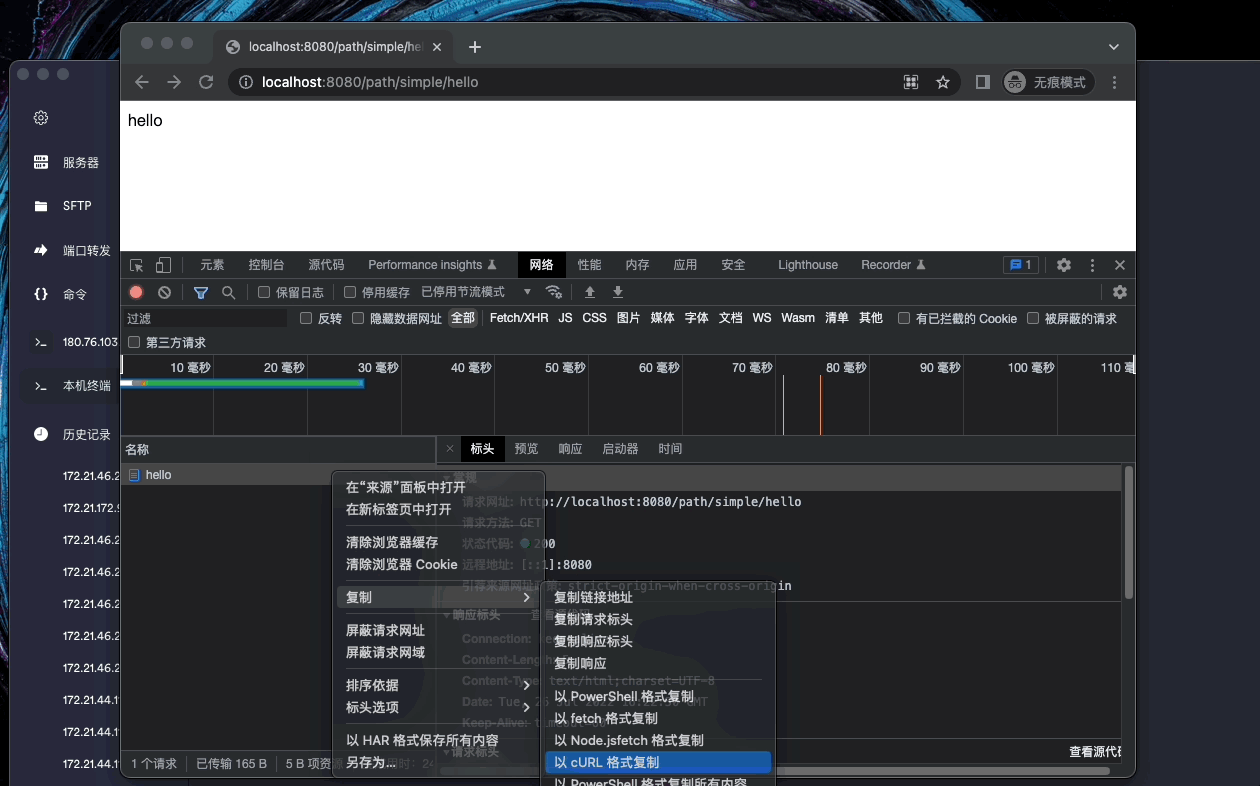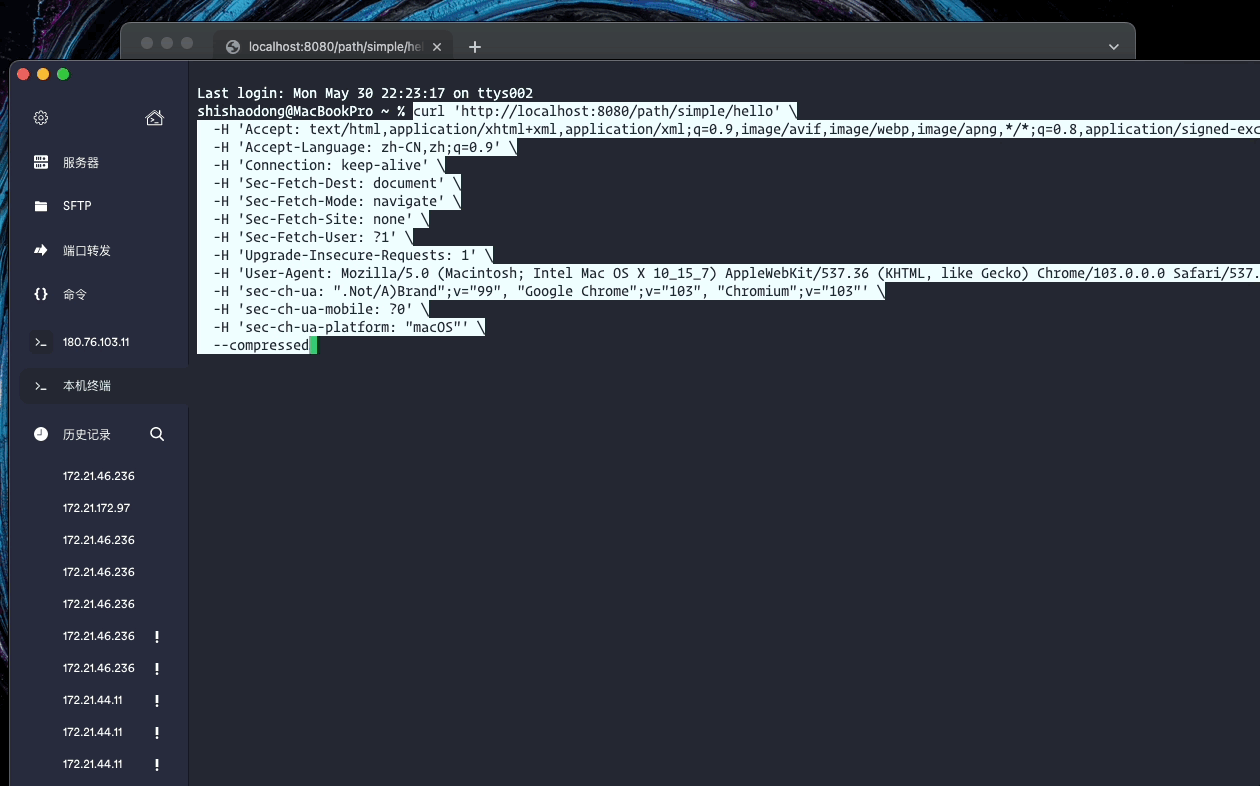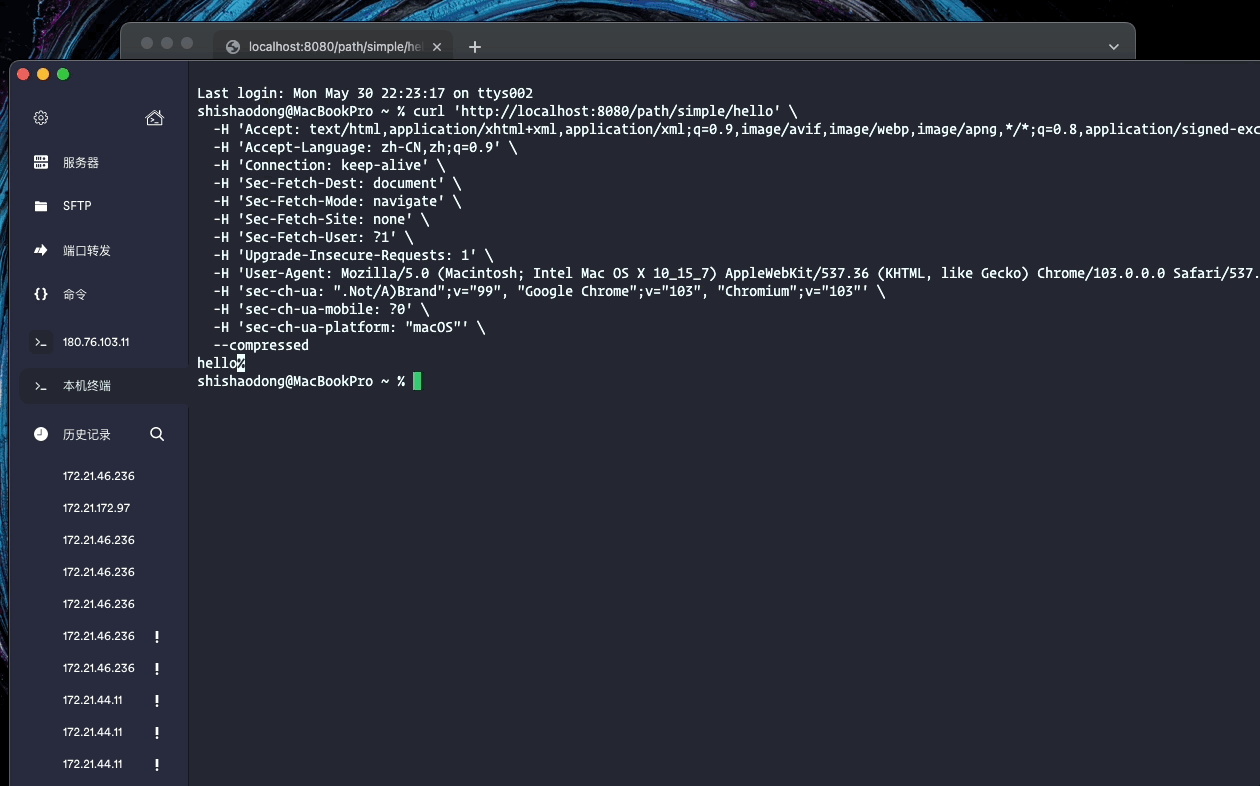
2.6. header 常见参数
| 类型 | 关键字 | 说明 |
|---|---|---|
请求头 |
accept |
表示可以接受的文件类型 |
请求头 |
accept-encoding |
表示当前浏览器可以接受的数据编码,如果服务器吐出的数据不是浏览器可接受的编码 |
请求头 |
Cookie |
很多和用户相关的信息都存在 Cookie 里,用户在向服务器发送请求数据时会带上 |
请求头 |
user-agent |
表示浏览器的版本信息。 |
请求头 |
content-encoding |
表示返回内容的压缩编码类型,如“Content-Encoding :gzip”表示这次回包是以 gzip 格式压缩编码的,这种压缩格式可以减少流量的消耗。 |
请求头 |
Authorization |
授权信息 |
请求头 |
content-type |
表示后面的文档属于什么MIME类型 |
请求头 |
Referer |
包含一个URL,用户从该URL代表的页面出发访问当前请求的页面 |
响应头 |
content-type |
表示后面的文档属于什么MIME类型 |
响应头 |
set-cookie |
知道这是服务器给的身份标识,于是就保存起来,下次再请求的时候就自动把这个值放进 Cookie 字段里发给服务器 |
2.7. 状态码
2xx:成功 3xx:重定向 4xx:客户端错误 5xx:服务器错误
2.8. GET 和 POST 基本用法和区别
| GET和POST是HTTP请求的两种基本方法。 |
2.8.1. 要说它们的区别,下面是“标准答案”:
-
GET在浏览器回退时是无害的,而POST会再次提交请求。
-
GET请求会被浏览器主动cache,而POST不会,除非手动设置。
-
GET请求只能进行url编码,而POST支持多种编码方式。
-
GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
-
对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
-
GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
-
GET参数通过URL传递,POST放在Request body中。
GET和POST是什么?HTTP协议中的两种发送请求的方法。 HTTP是什么?HTTP是基于TCP/IP的关于数据如何在万维网中如何通信的协议。 HTTP的底层是TCP/IP。所以GET和POST的底层也是TCP/IP,也就是说,GET/POST都是TCP链接。 GET和POST能做的事情是一样一样的。你要给GET加上request body,给POST带上url参数,技术上是完全行的通的。 那么,“标准答案”里的那些区别是怎么回事?
在我大万维网世界中,TCP就像汽车,我们用TCP来运输数据,它很可靠,从来不会发生丢件少件的现象。
但是如果路上跑的全是看起来一模一样的汽车,那这个世界看起来是一团混乱,送急件的汽车可能被前面满载货物的汽车拦堵在路上,整个交通系统一定会瘫痪。 为了避免这种情况发生,交通规则HTTP诞生了。
HTTP给汽车运输设定了好几个服务类别,有GET, POST, PUT, DELETE等等,HTTP规定,当执行GET请求的时候,要给汽车贴上GET的标签(设置method为GET),而且要求把传送的数据放在车顶上(url中)以方便记录。
HTTP只是个行为准则,而TCP才是GET和POST怎么实现的基本。
但是,我们只看到HTTP对GET和POST参数的传送渠道(url还是request body)提出了要求。“标准答案”里关于参数大小的限制又是从哪来的呢?
在我大万维网世界中,还有另一个重要的角色:运输公司。不同的浏览器(发起http请求)和服务器(接受http请求)就是不同的运输公司。
虽然理论上,你可以在车顶上无限的堆货物(url中无限加参数)。
但是运输公司可不傻,装货和卸货也是有很大成本的,他们会限制单次运输量来控制风险,数据量太大对浏览器和服务器都是很大负担。
业界不成文的规定是,(大多数)浏览器通常都会限制url长度在2K个字节,而(大多数)服务器最多处理64K大小的url。 超过的部分,恕不处理。
如果你用GET服务,在request body偷偷藏了数据,不同服务器的处理方式也是不同的,有些服务器会帮你卸货,读出数据,有些服务器直接忽略,所以,虽然GET可以带request body,也不能保证一定能被接收到哦。
好了,现在你知道,GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。
GET和POST还有一个重大区别,简单的说: GET产生一个TCP数据包;POST产生两个TCP数据包。 长的说:对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);而对于POST,浏览器先发送 header,服务器响应 100 continue,浏览器再发送 data,服务器响应200 ok(返回数据)。 也就是说,GET只需要汽车跑一趟就把货送到了,而POST得跑两趟,第一趟,先去和服务器打个招呼“嗨,我等下要送一批货来,你们打开门迎接我”,然后再回头把货送过去。
2.9. http协议是无状态的
每个请求都是完全独立的,每个请求包含了处理这个请求所需的完整的数据,发送请求不涉及到状态变更。

3. Linux 基础
3.1. 需要掌握 Linux 命令
| 序号 | 命令 | 示例 | 说明 |
|---|---|---|---|
1 |
cat |
查看文件 |
cat xxx.txt |
2 |
grep |
抓取指定数据,经常和管道一起用 |
Column 4, row 2 |
3 |
ping |
测试目标 IP 能不能到达, 目标 IP 可能禁ping |
Column 4, row 3 |
4 |
telnet |
测试端口通不通 |
Column 4, row 4 |
5 |
mount |
挂载磁盘 |
Column 4, row 5 |
6 |
touch |
创建文件 |
Column 4, row 6 |
7 |
chmod |
修改文件/目录权限 |
Column 4, row 6 |
7 |
kill |
杀掉进程 |
Column 4, row 6 |
8 |
tail |
查看文件 |
Column 4, row 6 |
9 |
wc |
count 文件行数 |
Column 4, row 6 |
10 |
find |
查找文件 |
Column 4, row 6 |
11 |
systemctl |
服务相关 启动/重启/停止 |
Column 4, row 6 |
12 |
ifconfig |
查看网卡 IP 信息 |
Column 4, row 6 |
13 |
dig |
查看路由信息 |
Column 4, row 6 |
13 |
ps |
查看进程 |
Column 4, row 6 |
14 |
free |
查看内存 |
Column 4, row 6 |
15 |
top |
查看进程和内存 |
Column 4, row 6 |
16 |
vim |
编辑文本文件 |
Column 4, row 6 |
17 |
history |
查看历史命令 |
Column 4, row 6 |
18 |
scp |
传输文件 |
Column 4, row 6 |
19 |
crontab |
定时任务 |
Column 4, row 6 |
20 |
cd |
进入文件夹 |
Column 4, row 6 |
22 |
mkdir |
创建文件夹 |
Column 4, row 6 |
22 |
df |
查看磁盘 |
Column 4, row 6 |
22 |
ssh |
登录服务器 |
Column 4, row 6 |
23 |
ln |
创建链接 |
Column 4, row 6 |
3.2. 文件目录结构
| 序号 | 目录 | 说明 | 备注 |
|---|---|---|---|
1 |
/dev |
设备文件 |
Column 4, row 1 |
2 |
/etc |
大多数配置文件 |
Column 4, row 2 |
3 |
/home |
普通用户的家目录 |
Column 4, row 2 |
4 |
/lib |
32位函数库 |
Column 4, row 2 |
5 |
/lib64 |
64位库 |
Column 4, row 2 |
6 |
/media |
手动临时挂载点 |
Column 4, row 2 |
7 |
/mnt |
手动临时挂载点 |
Column 4, row 2 |
8 |
/opt |
第三方软件安装位置 |
Column 4, row 2 |
9 |
/proc |
进程信息及硬件信息 |
Column 4, row 2 |
10 |
/root |
临时设备的默认挂载点 |
Column 4, row 2 |
11 |
/sbin |
系统管理命令 |
Column 4, row 2 |
12 |
/srv |
数据 |
Column 4, row 2 |
13 |
/var |
数据 |
Column 4, row 2 |
14 |
/sys |
内核相关信息 |
Column 4, row 2 |
15 |
/tmp |
临时文件 |
Column 4, row 2 |
16 |
/usr |
用户相关设定 |
Column 4, row 2 |
3.3. 关闭 防火墙
3.4. 关闭 selinux
3.5. 不能联网安装文件
如果遇到不能联网的虚拟机,安装软件方法 --downloadonly 表示只下载,--downloaddir 指定下载的文件夹
安装文件
4. SpringBoot 工程初始化
4.1. 使用 IDEA 初始化工程

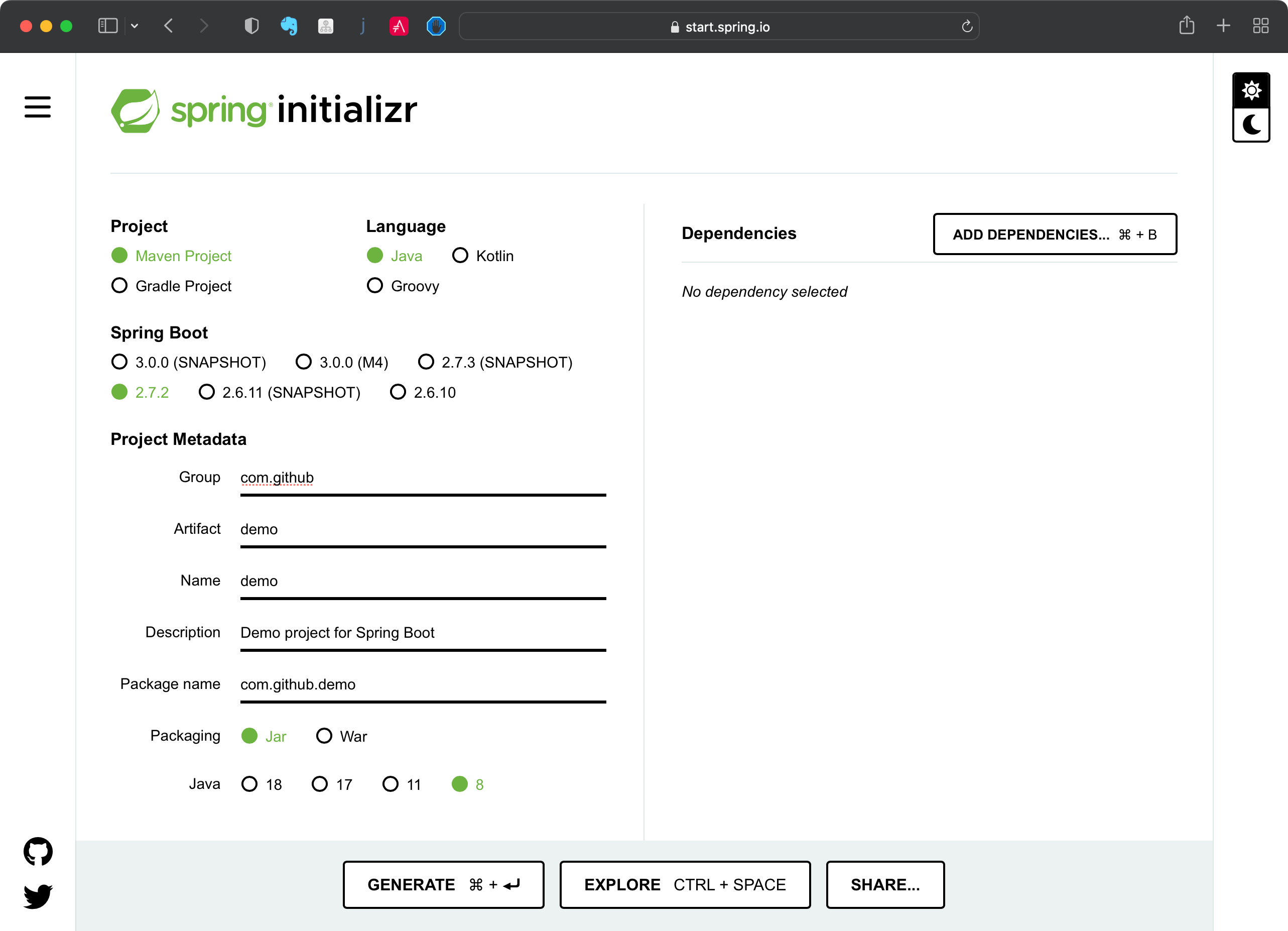
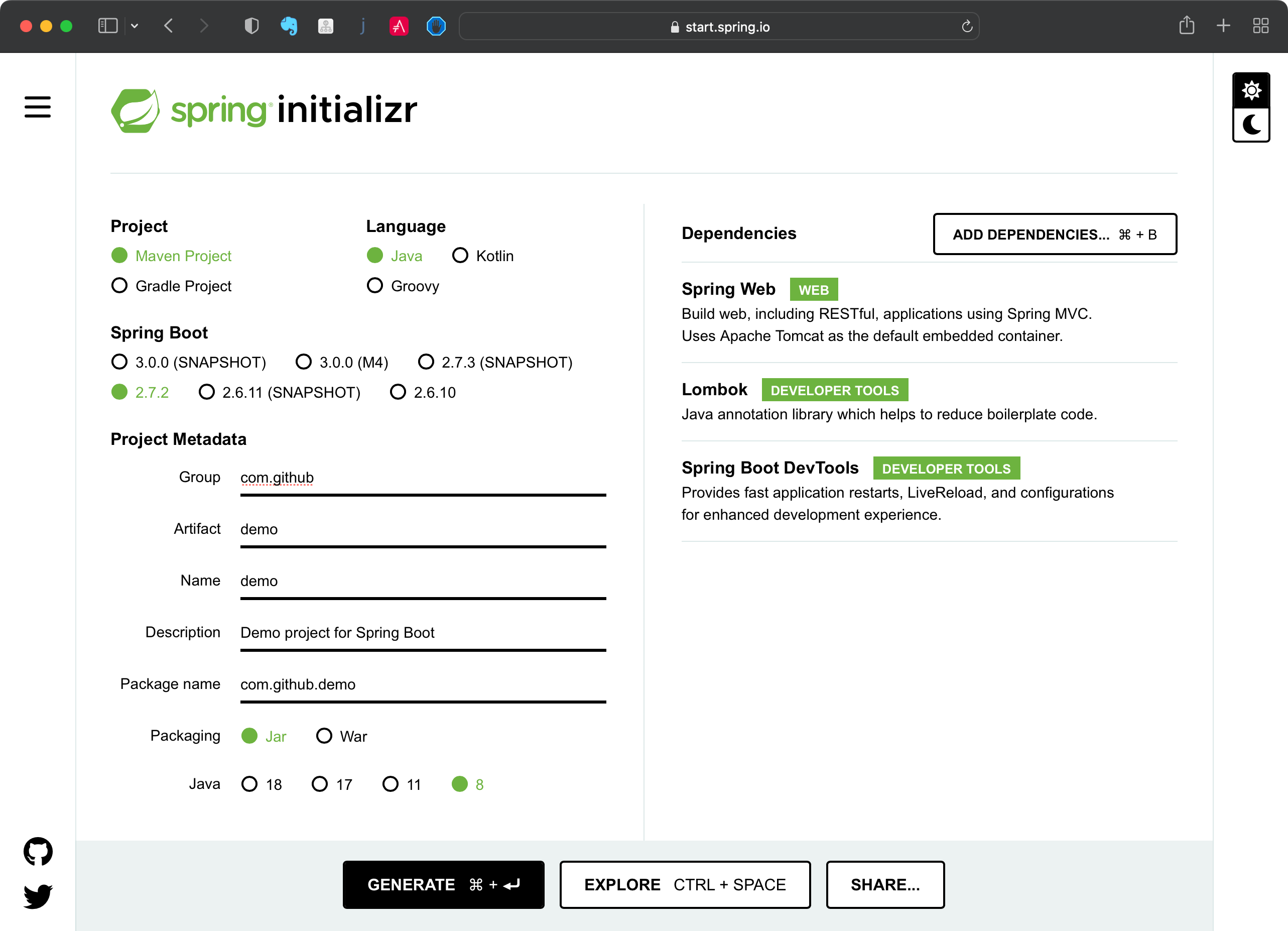
4.3. SpringBoot官方文档
5. IDEA 的一些插件 ⭐️
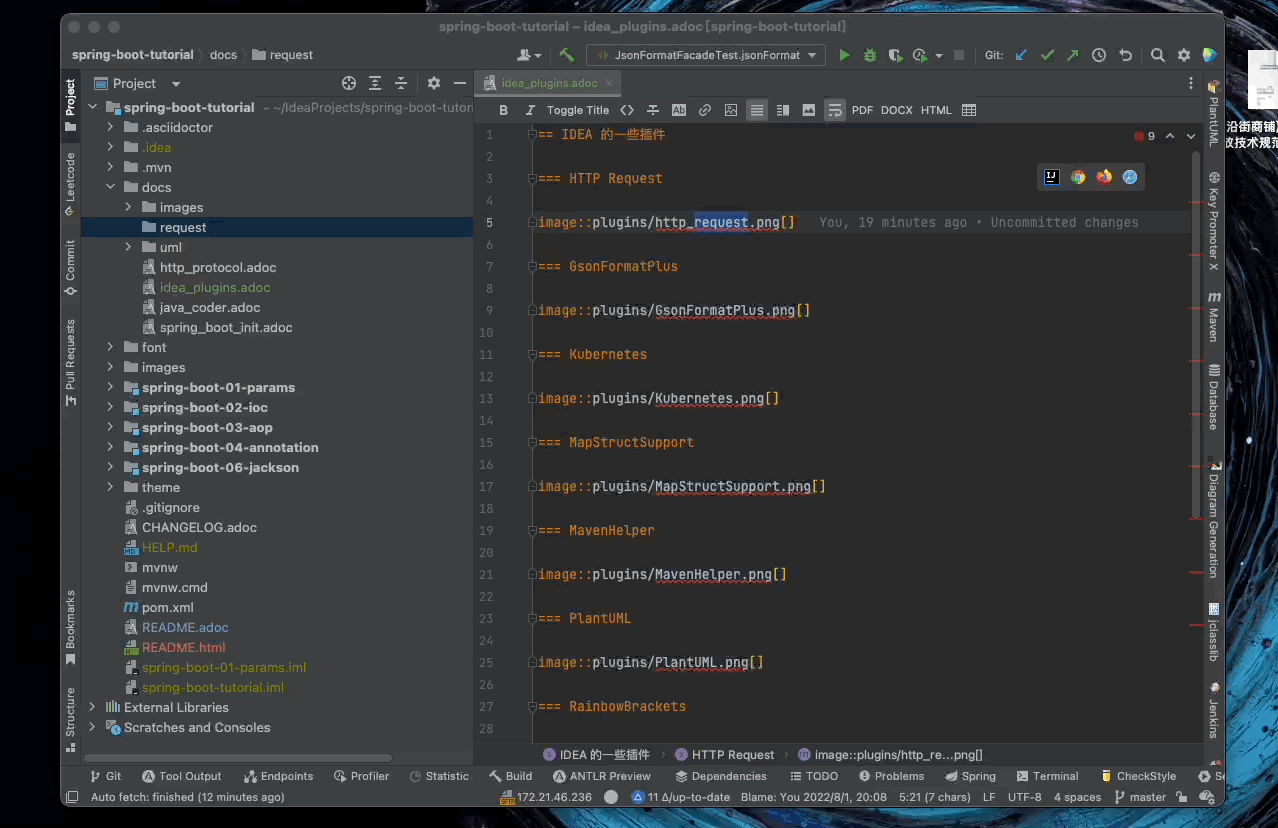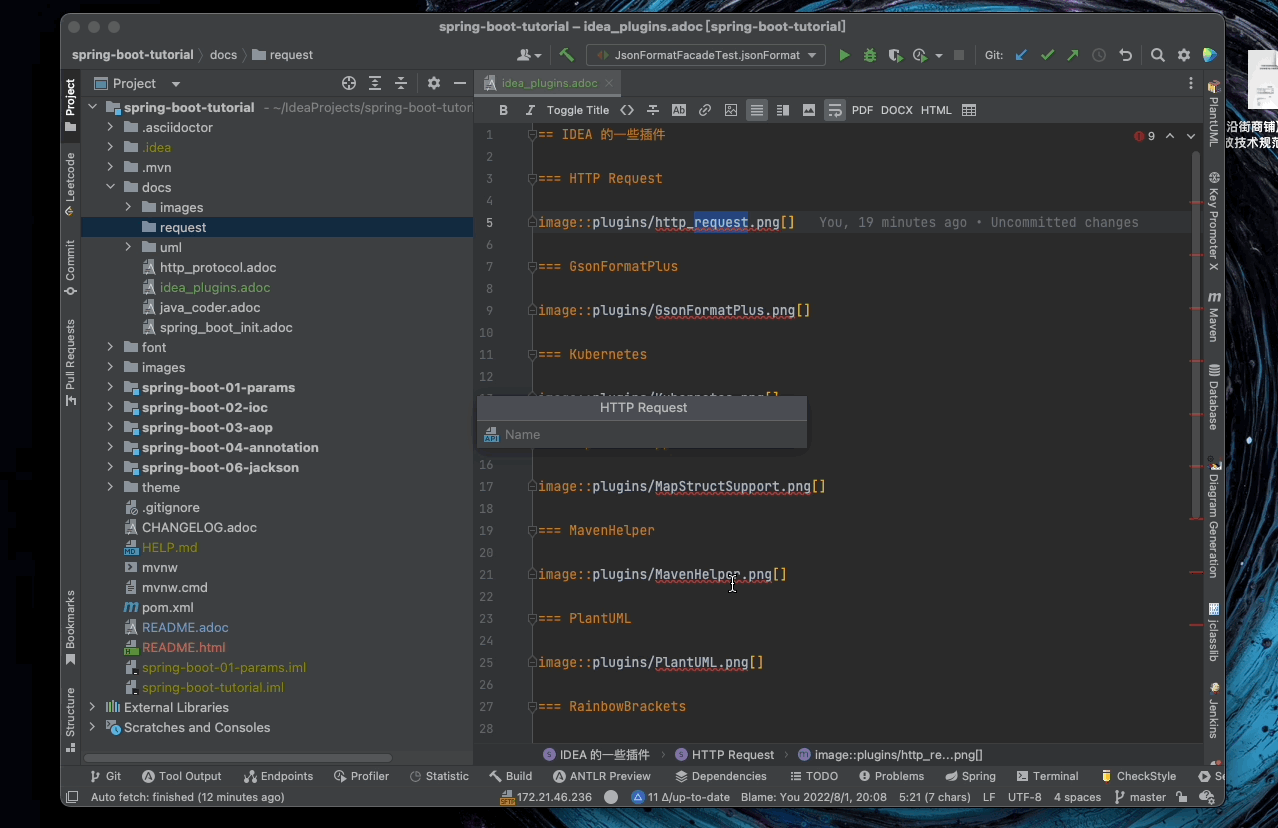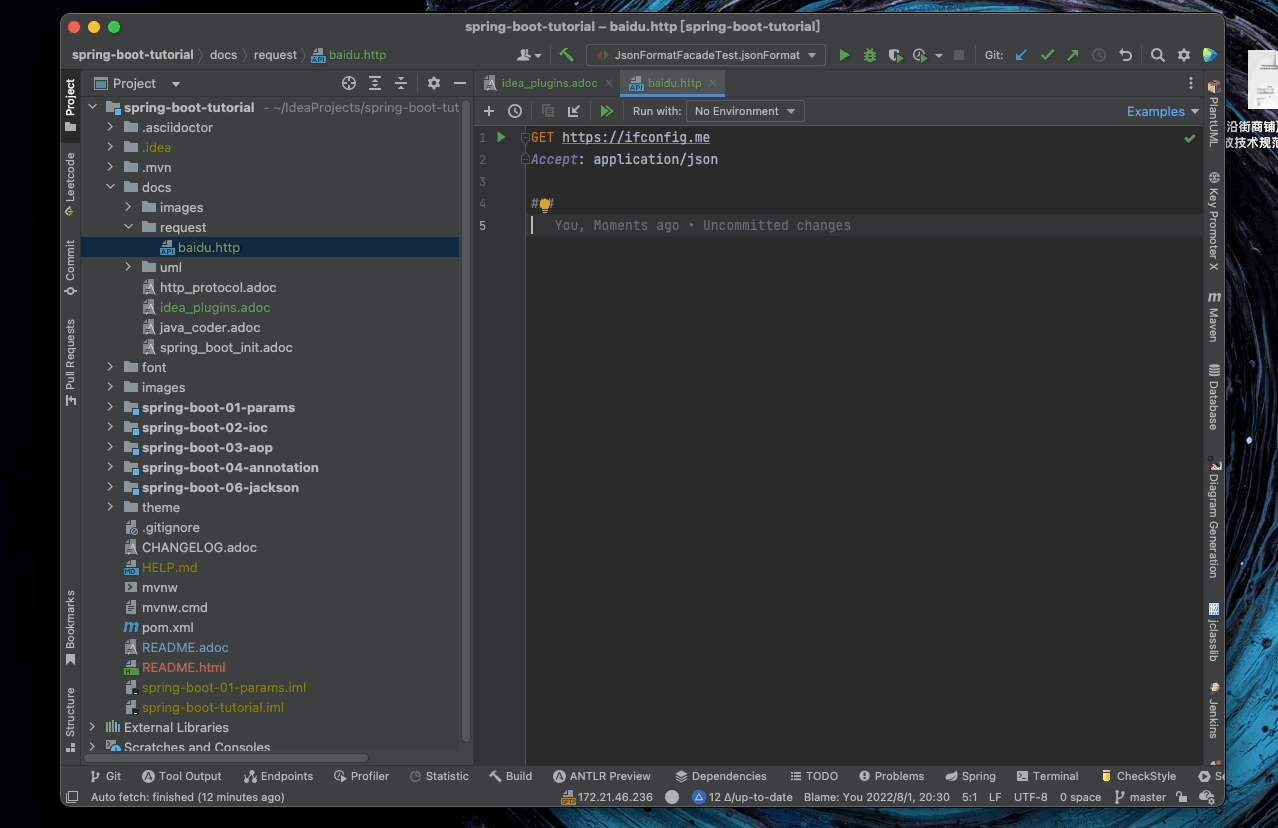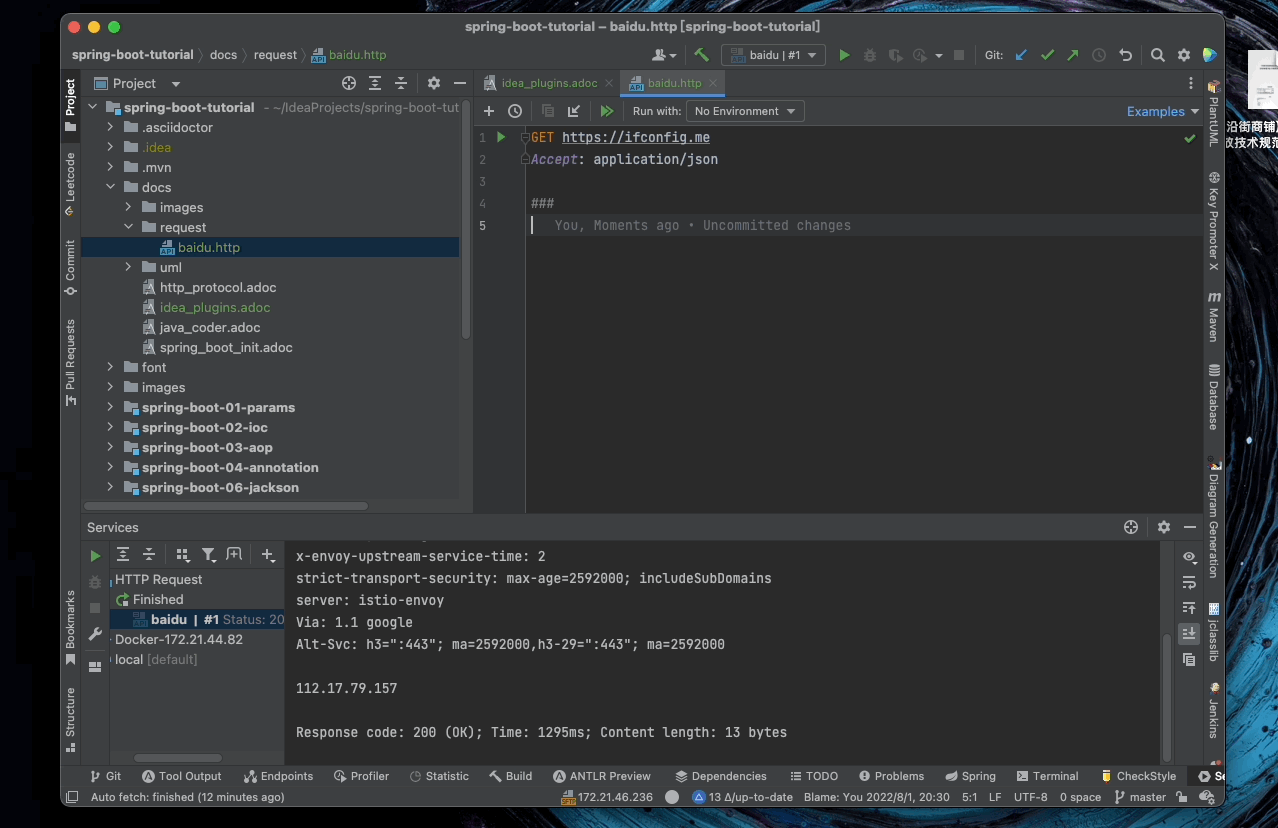
5.1. HTTP Request
使用 IDEA 发出 HTTP 请求
使用方法
5.2. GsonFormatPlus
将 JSON 格式的字符串直接转换成实体类
5.3. Kubernetes


5.4. MapStructSupport
5.5. MavenHelper
5.6. PlantUML
5.7. RainbowBrackets
5.8. SonarLint
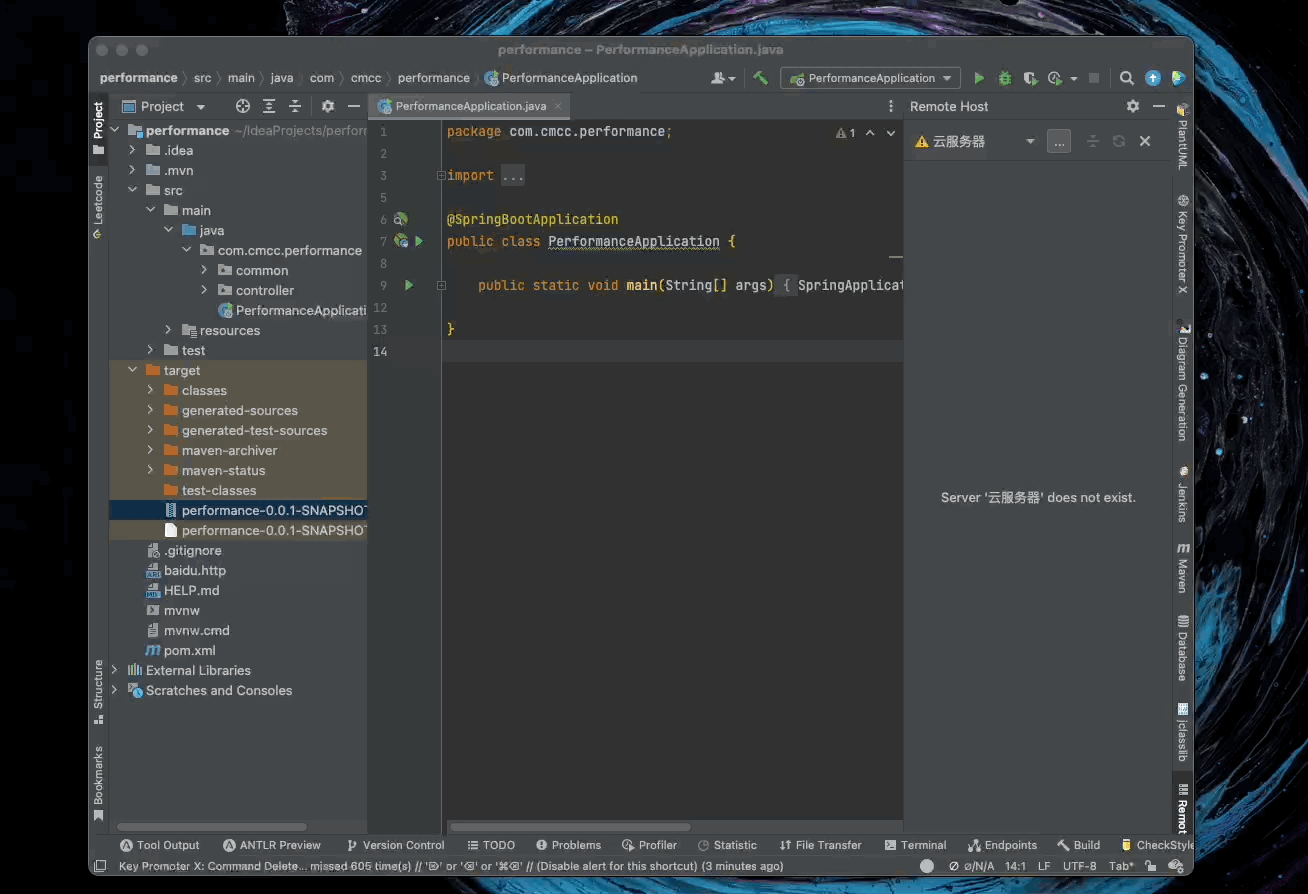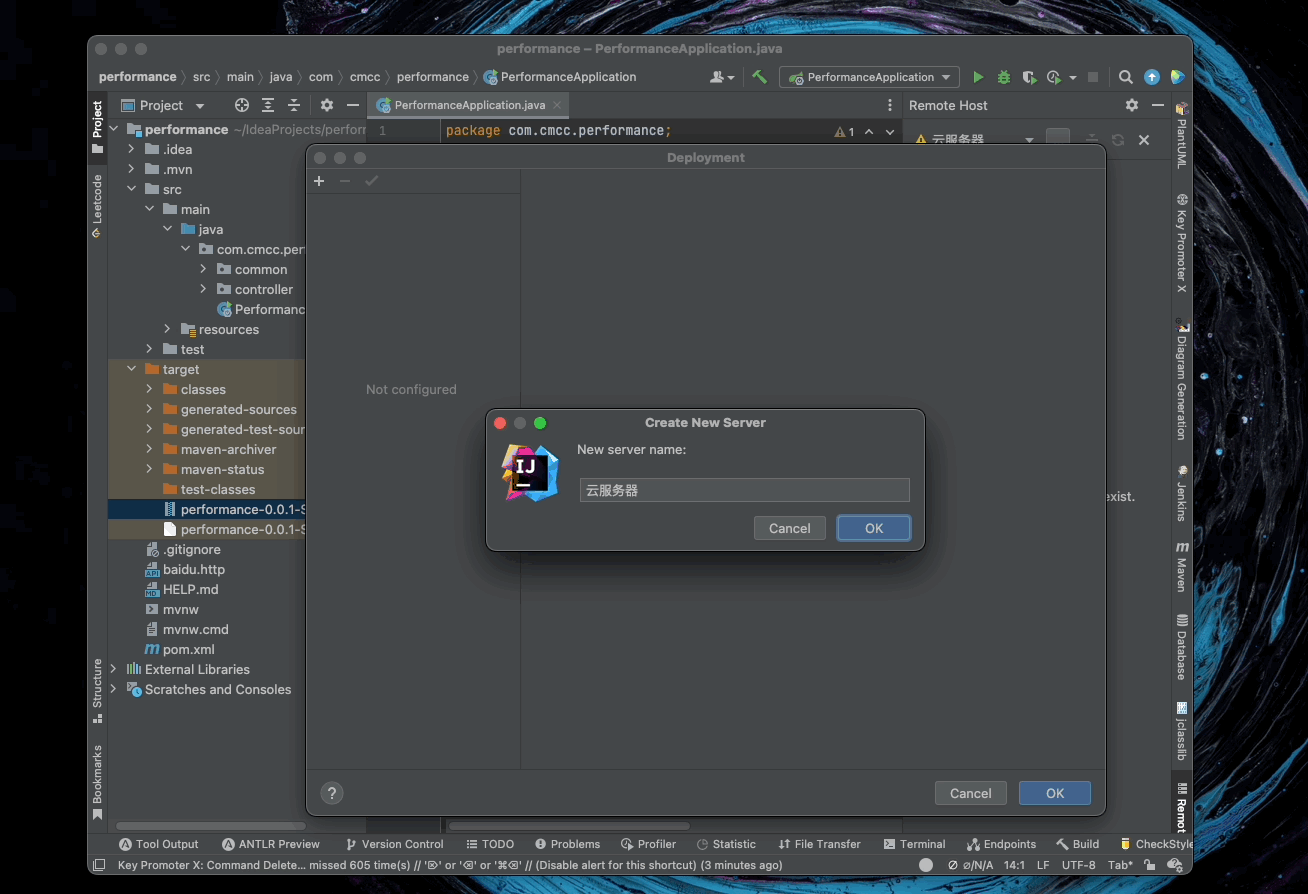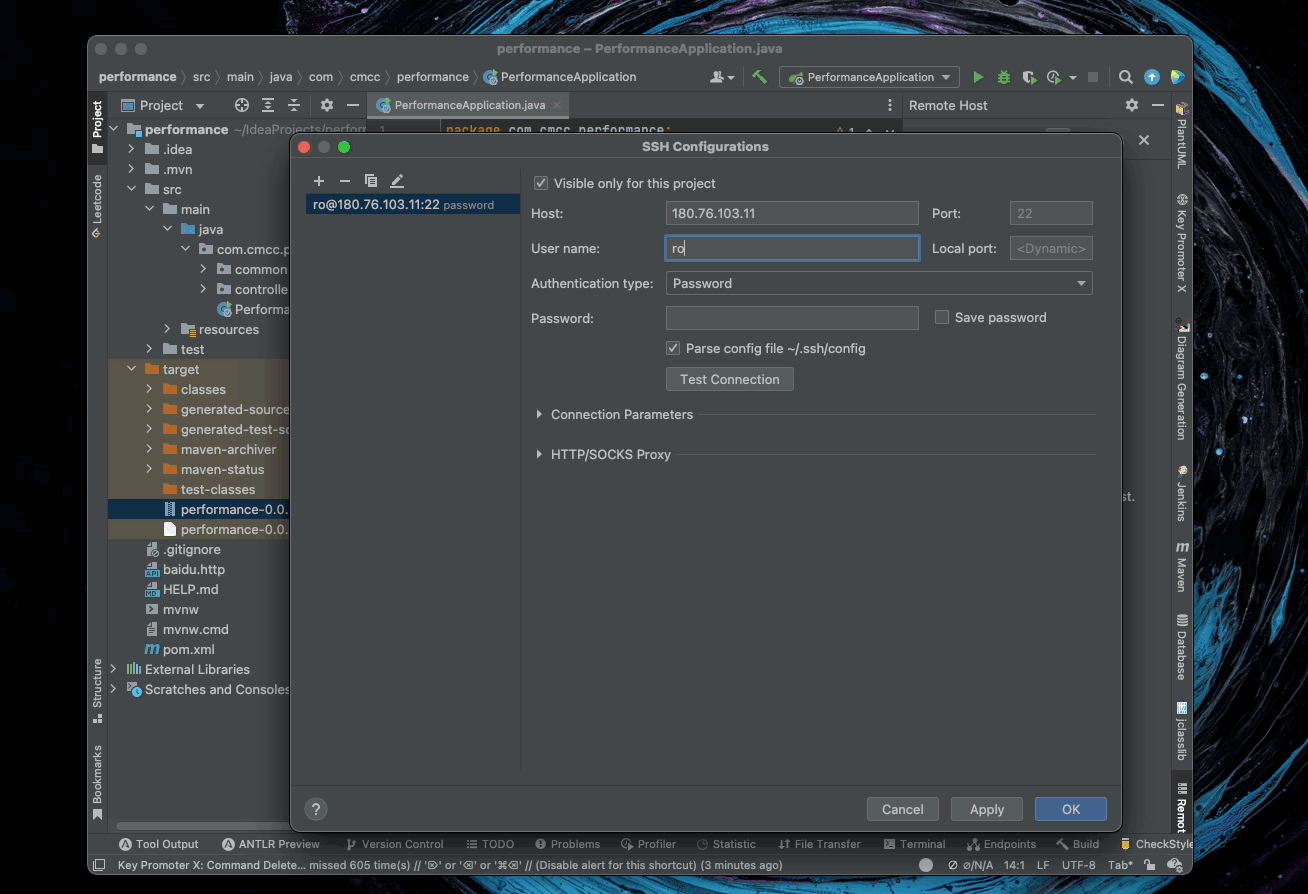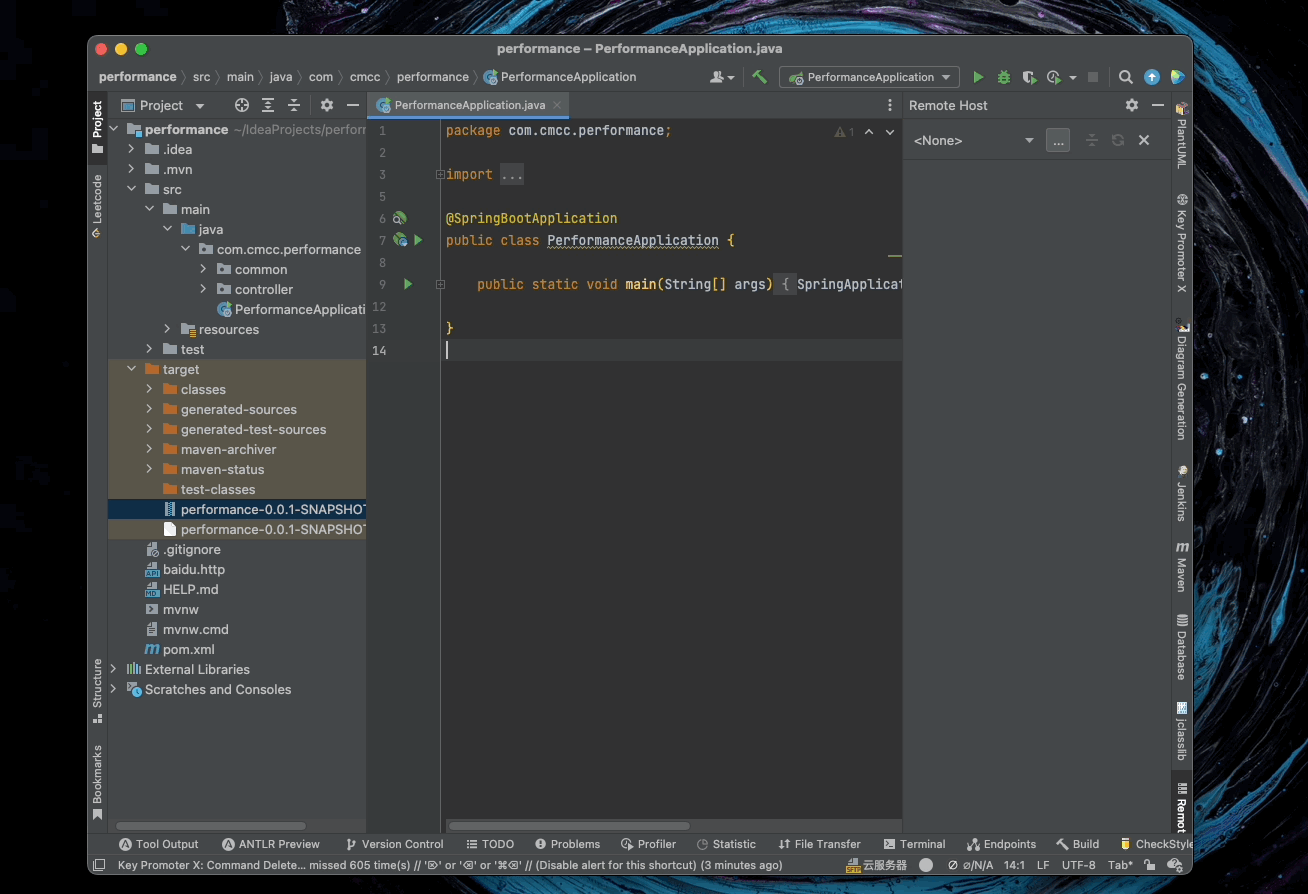
5.9. Deployment
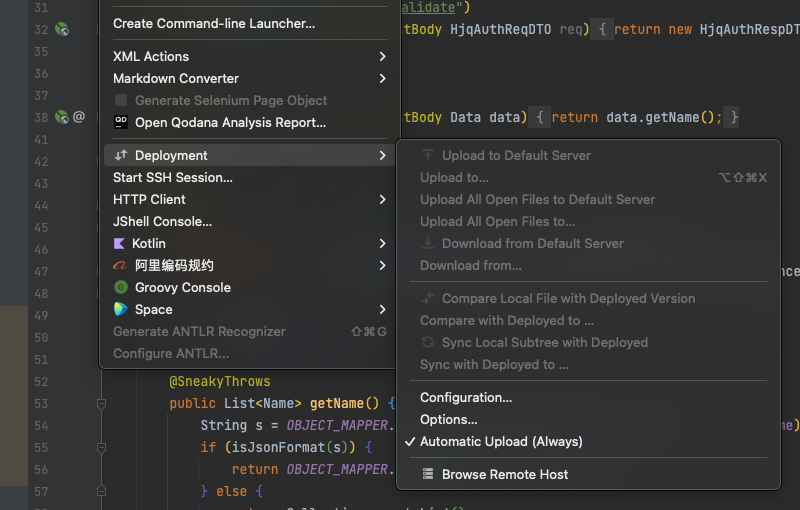
配置远程服务器
向远程服务器上传文件
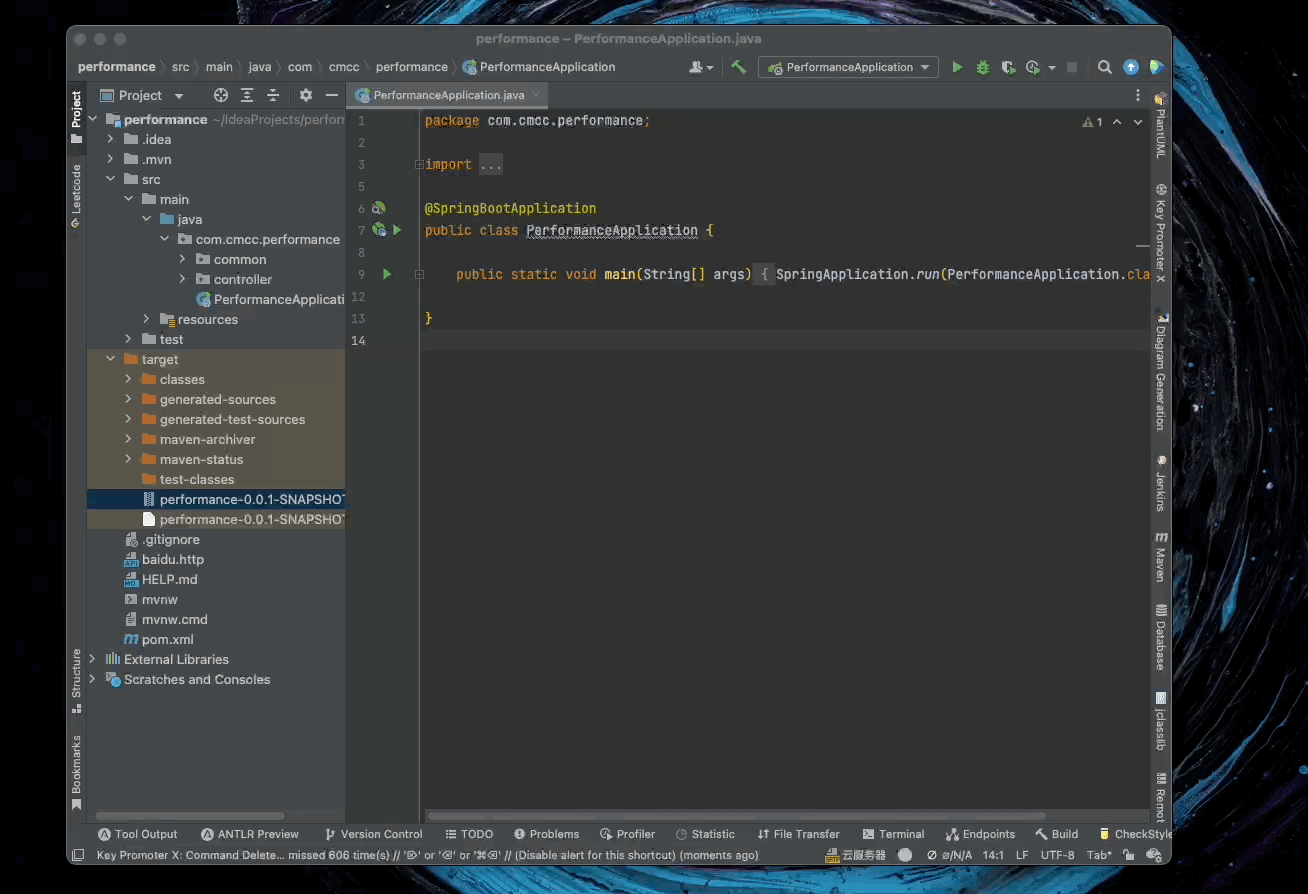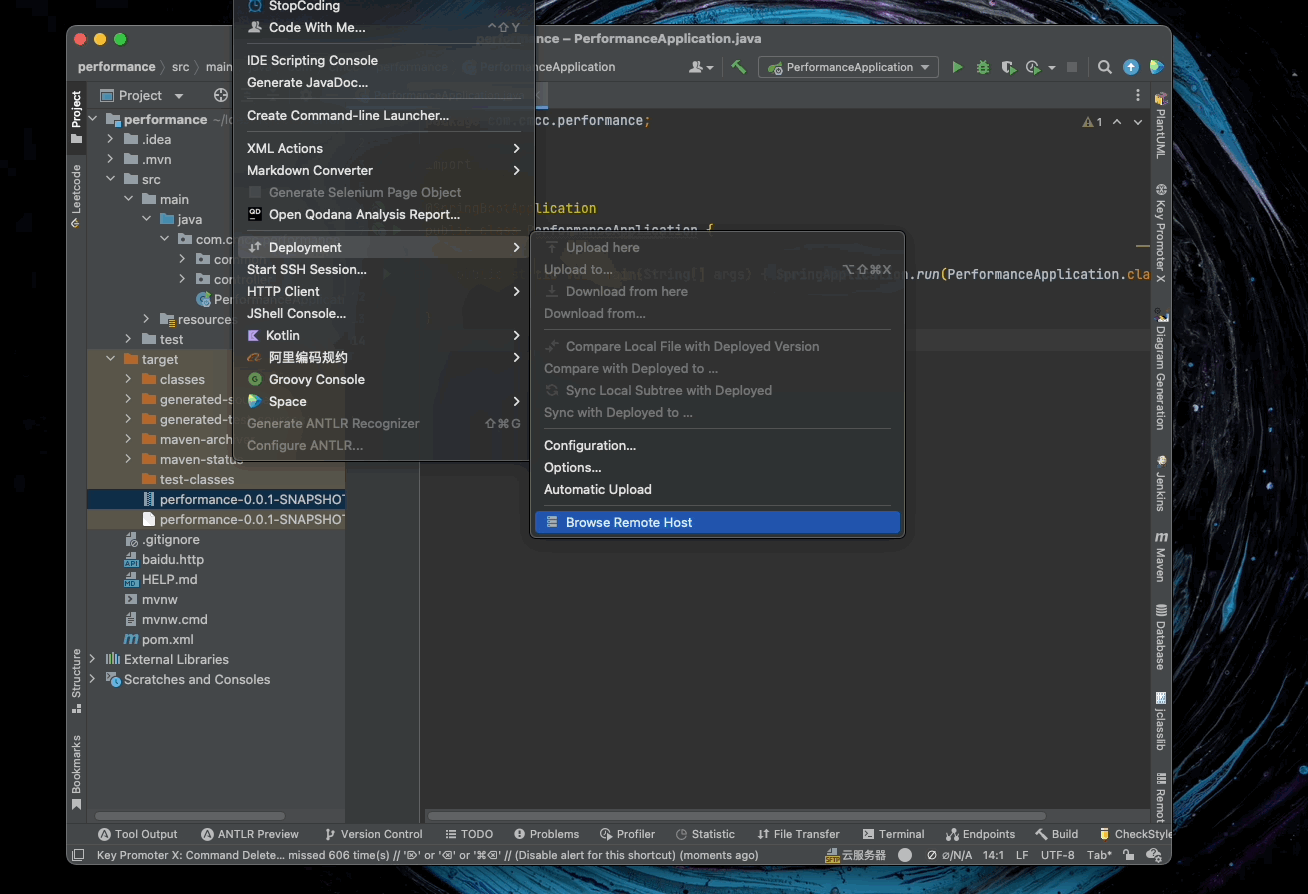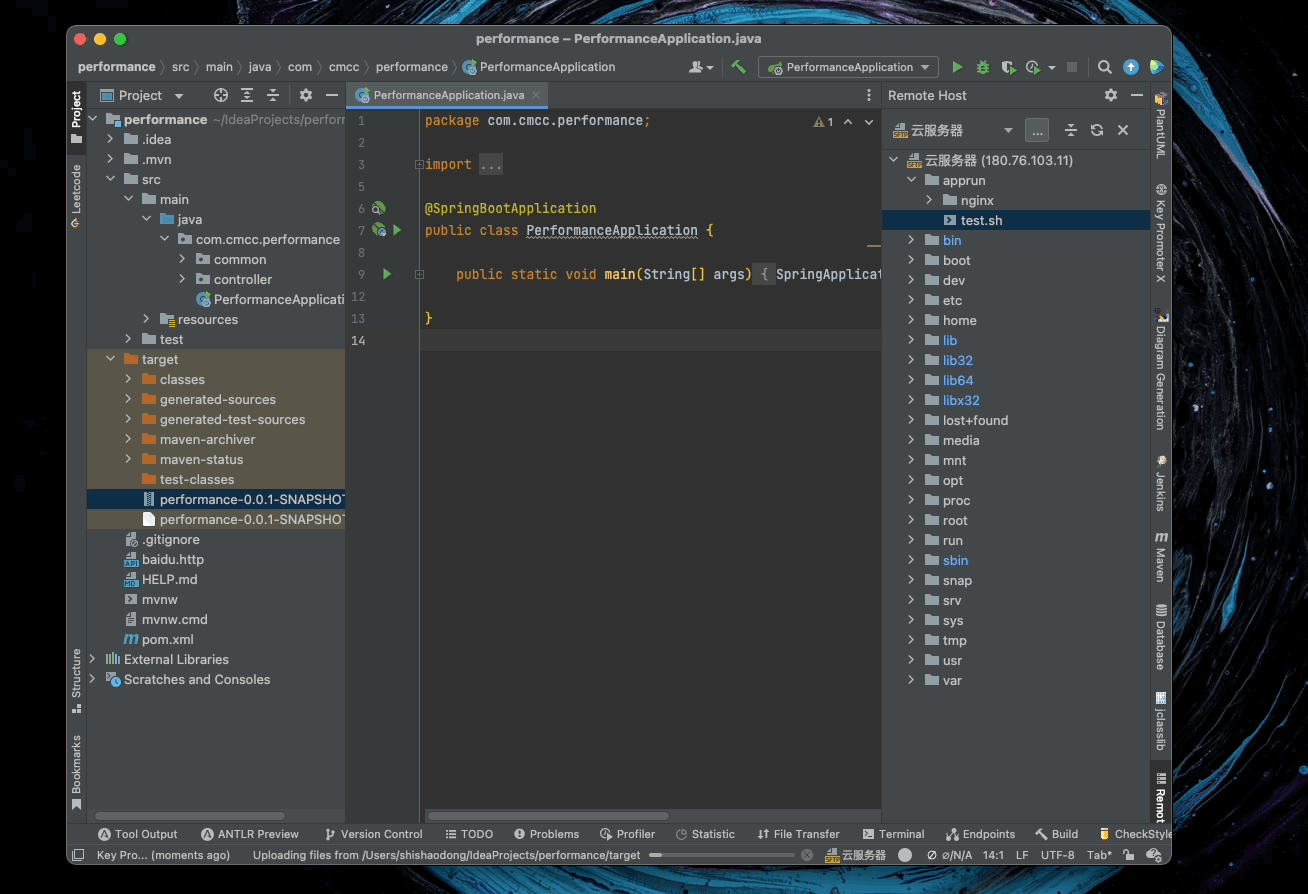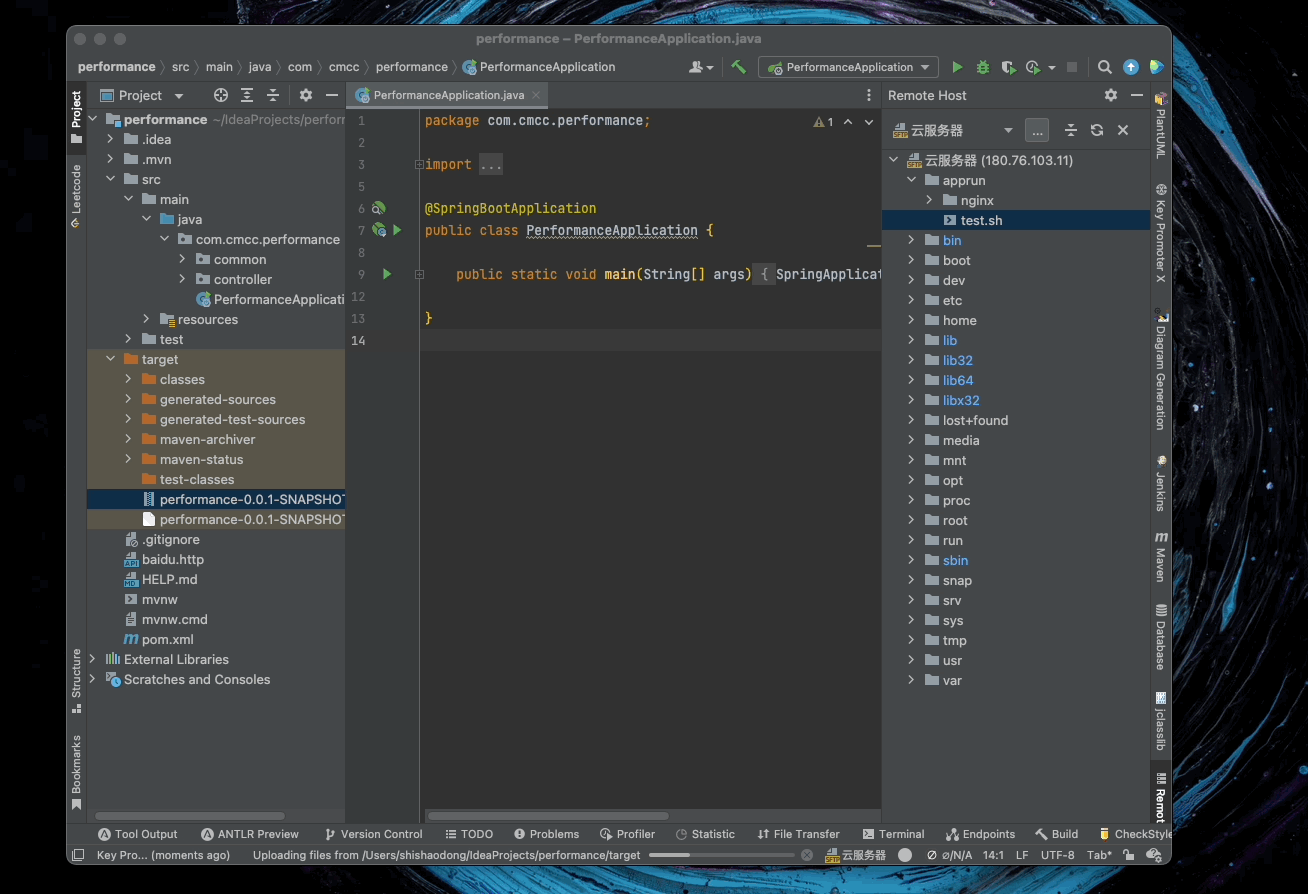
5.10. 本地 DEBUG
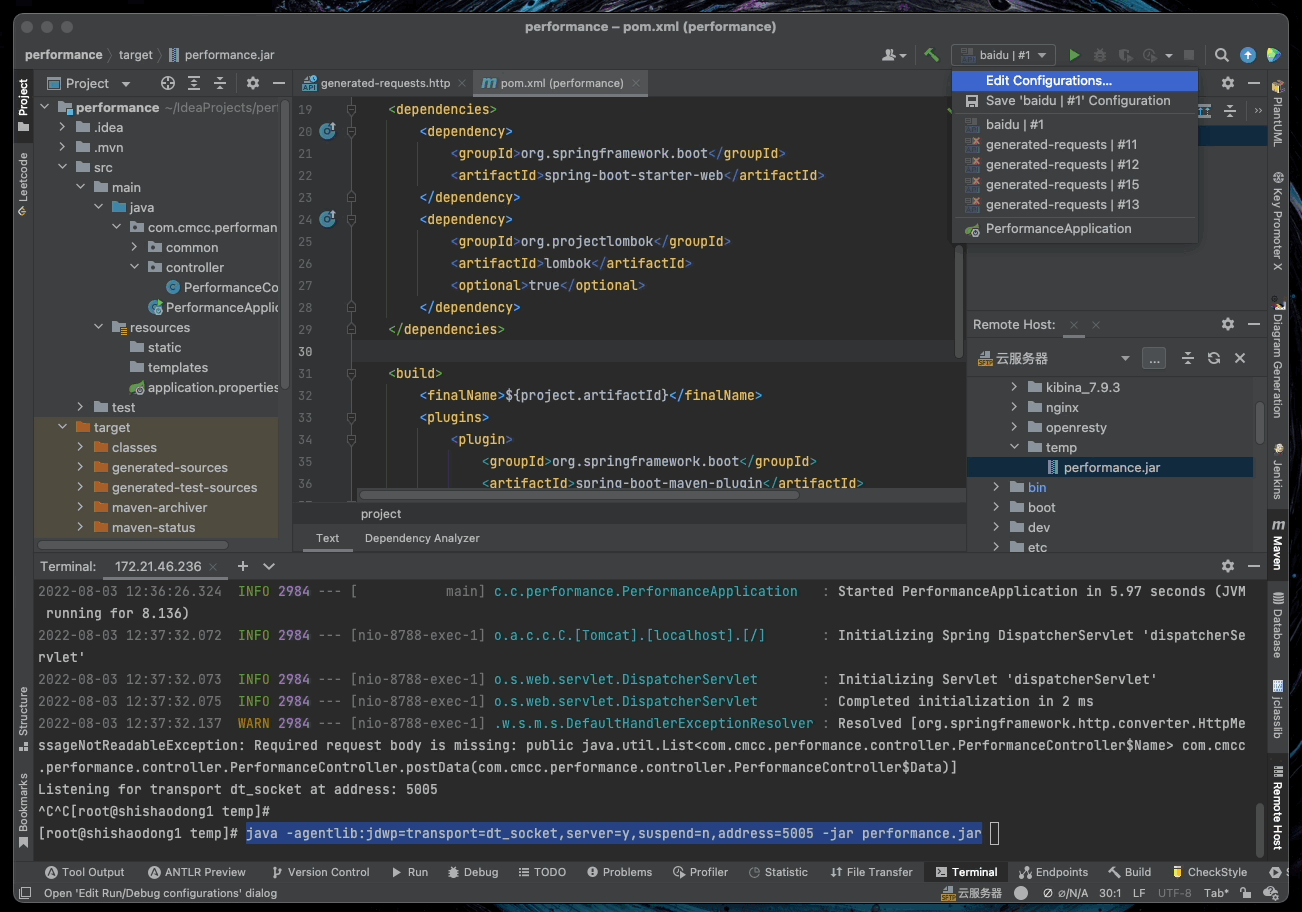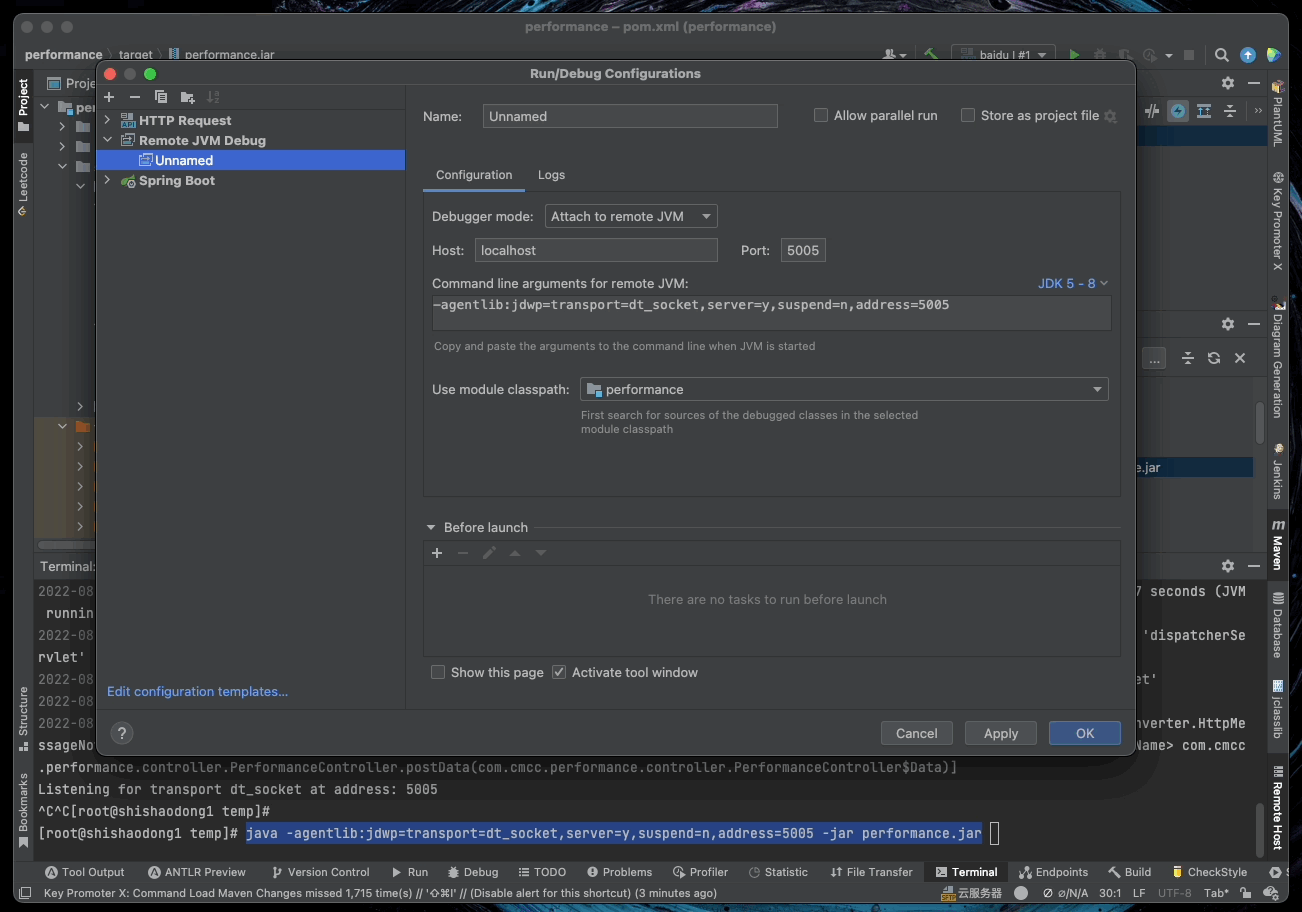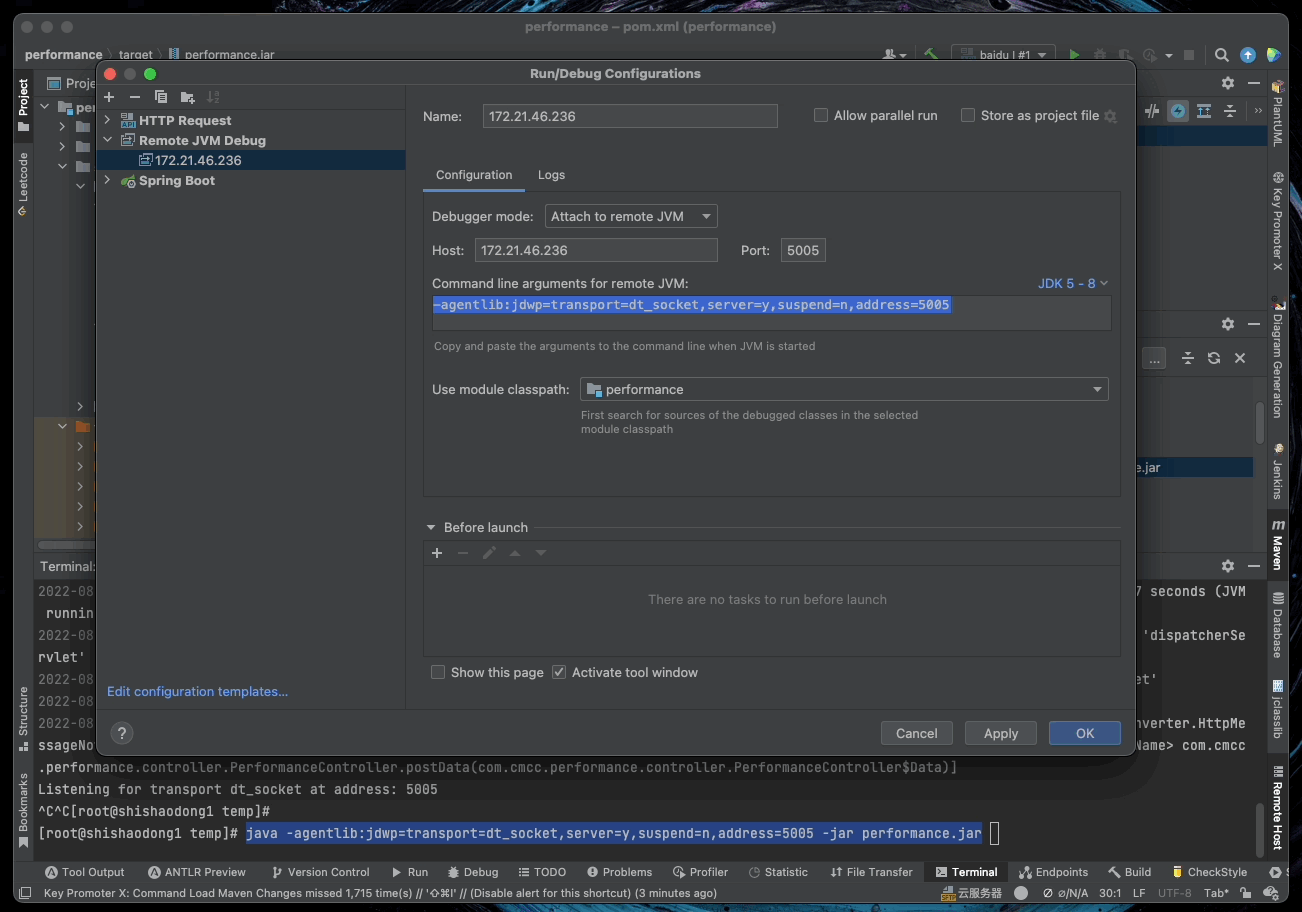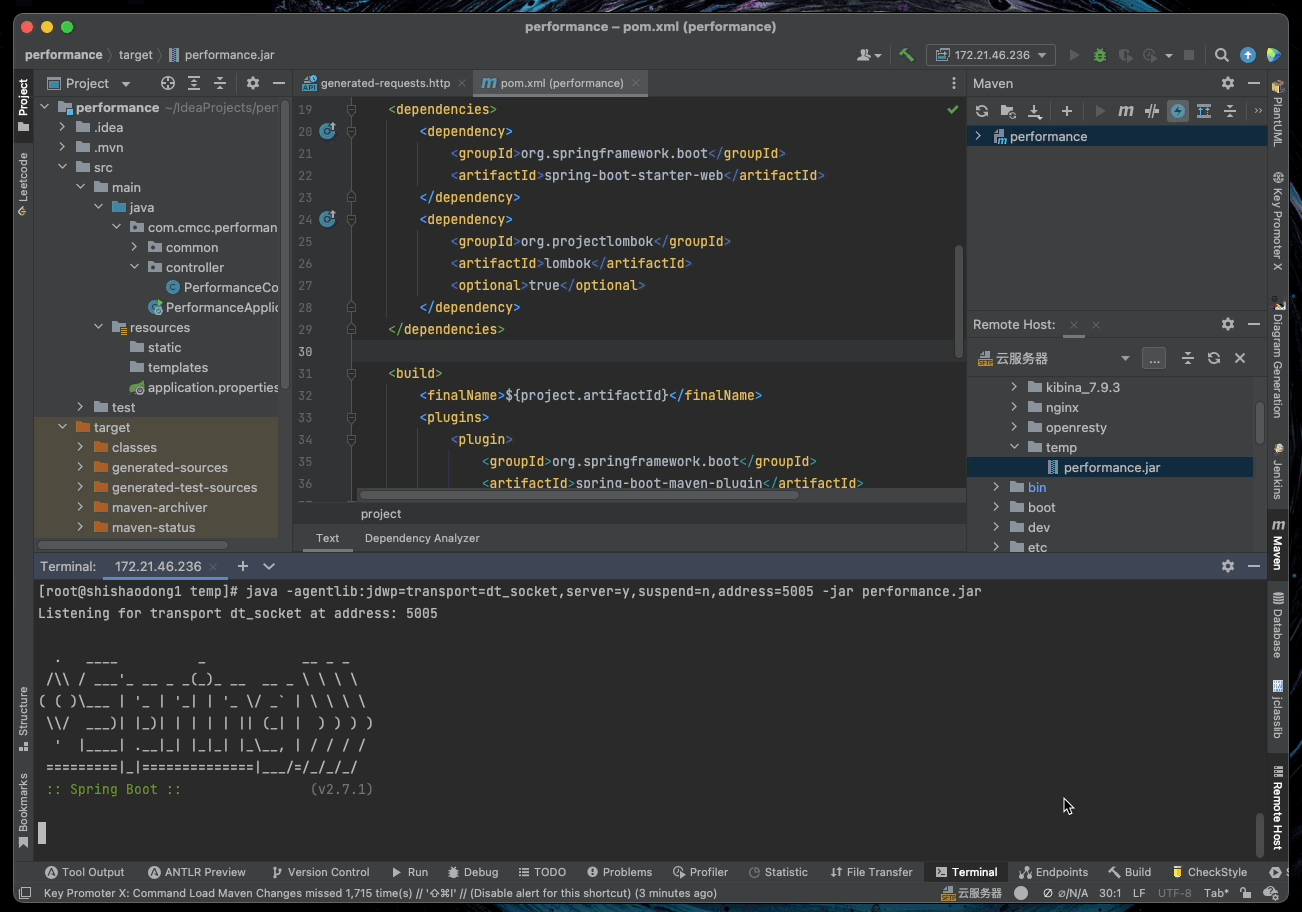
5.11. 远程 DEBUG
6. Javadoc
6.1. 错误示例
6.2. JDK 支持的 JavaDoc 标签
| 标签 | 描述 | 在 JDK/SDK 中引入 |
|---|---|---|
@author |
名称文本,仅限类和接口 |
1.0 |
{@code} |
显示文本,而不会将文本解释为 HTML 标记或嵌套的 javadoc 标签 |
1.5 |
{@docRoot} |
指明当前文档根目录的路径 |
1.3 |
@deprecated |
弃用文本,指名一个过期的类或成员,表明该类或方法不建议使用 |
1.0 |
@exception |
可能抛出异常的说明,一般用于方法注释 |
1.0 |
{@inheritDoc} |
从直接父类继承的注释 |
1.4 |
{@link} |
插入一个到另一个主题的链接 |
1.2 |
{@linkplain} |
插入一个到另一个主题的链接,但是该链接显示纯文本字体 |
1.4 |
{@literal} |
显示文本,而不会将文本解释为 HTML 标记或嵌套的 javadoc 标签 |
1.5 |
@param |
说明一个参数,仅限方法和构造器 |
1.0 |
@return |
说明返回值类型,仅限方法 |
1.0 |
@see |
指定一个到另一个主题的链接 |
1.0 |
@serial |
说明一个序列化属性 |
1.2 |
@serialData |
说明通过 writeObject() 和 writeExternal() 方法写的数据 |
1.2 |
@serialField |
说明一个 ObjectStreamField 组件 |
1.2 |
@since |
说明从哪个版本起开始有了这个函数 |
1.1 |
@throws |
和 @exception 标签一样. |
1.2 |
{@value} |
显示常量的值,该常量必须是 static 属性。 |
1.4 |
@version |
指定版本,仅限类和接口 |
1.0 |
6.3. IDEA 生成 JavaDoc
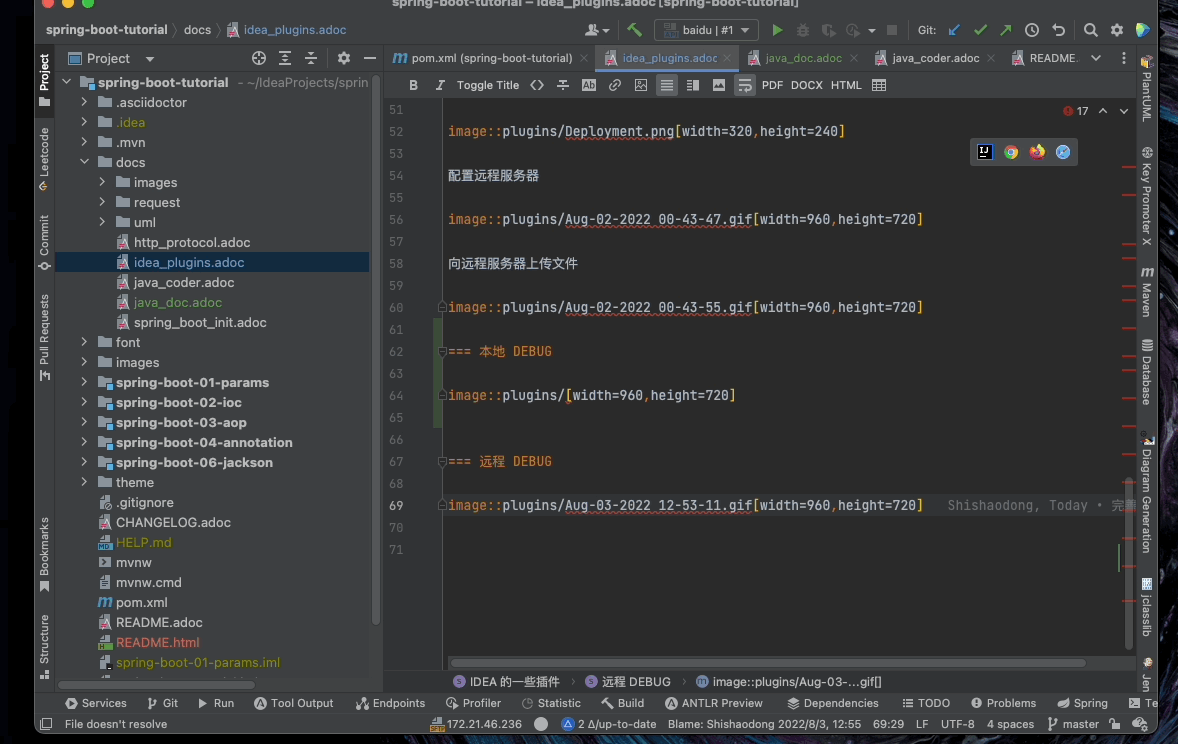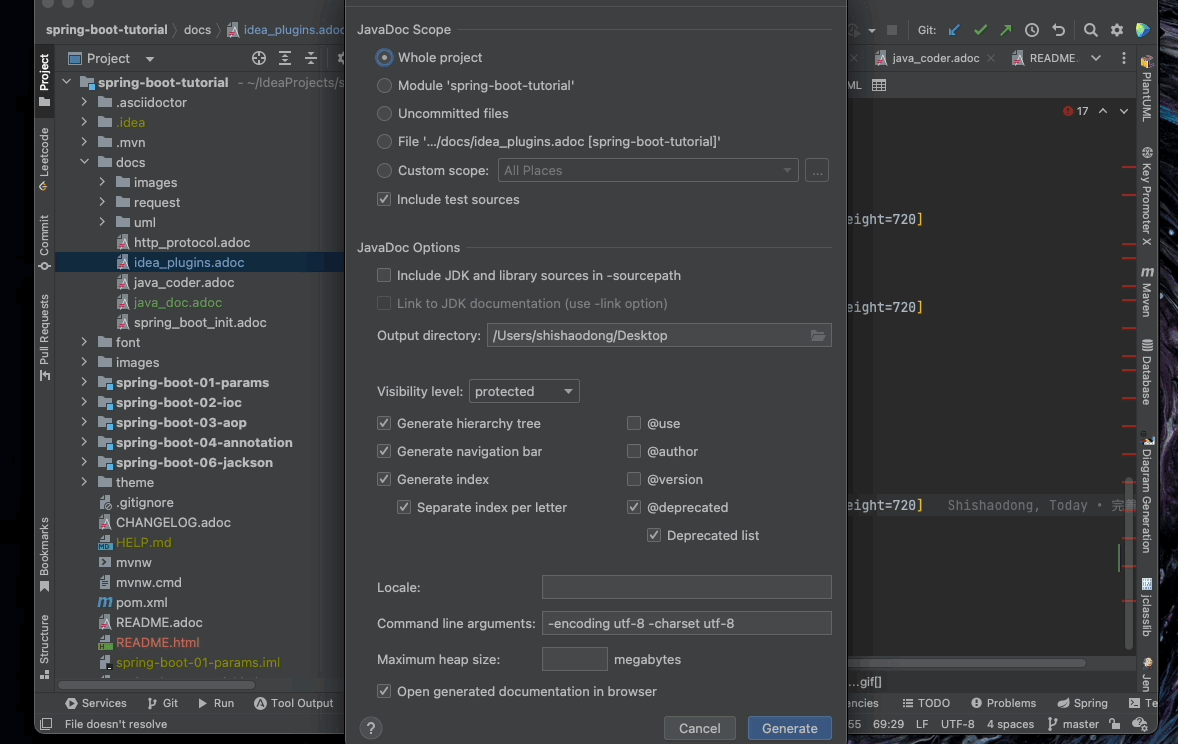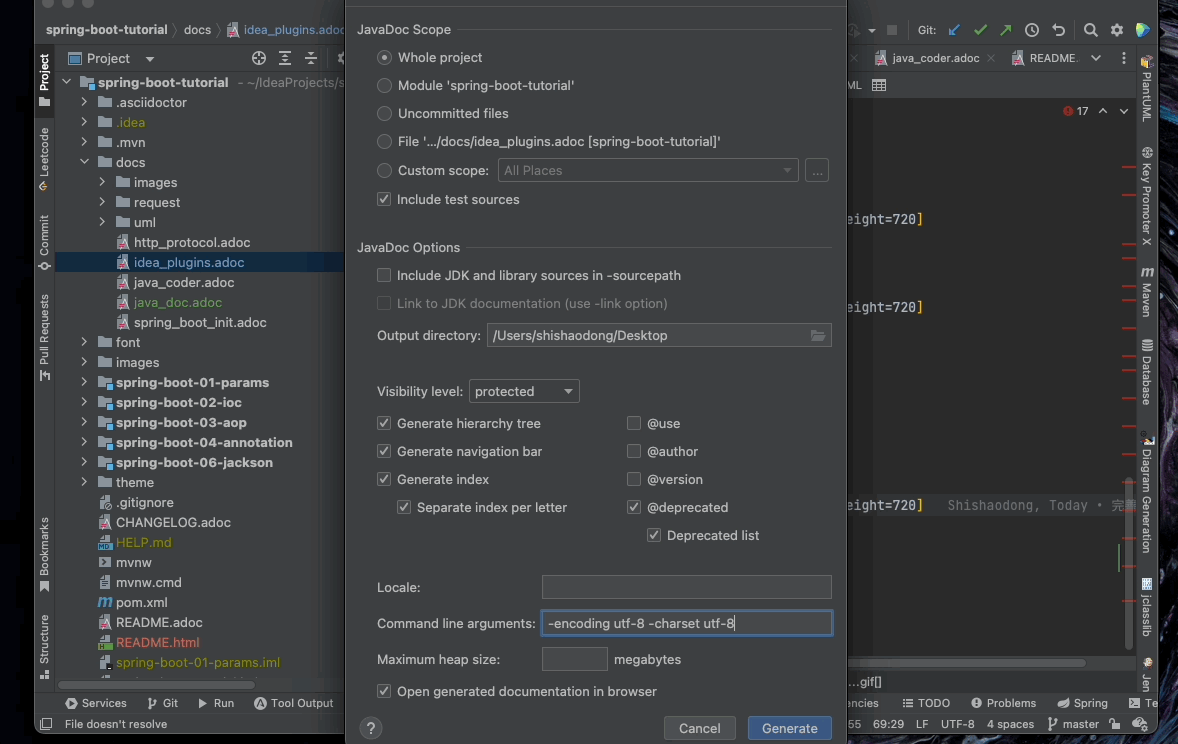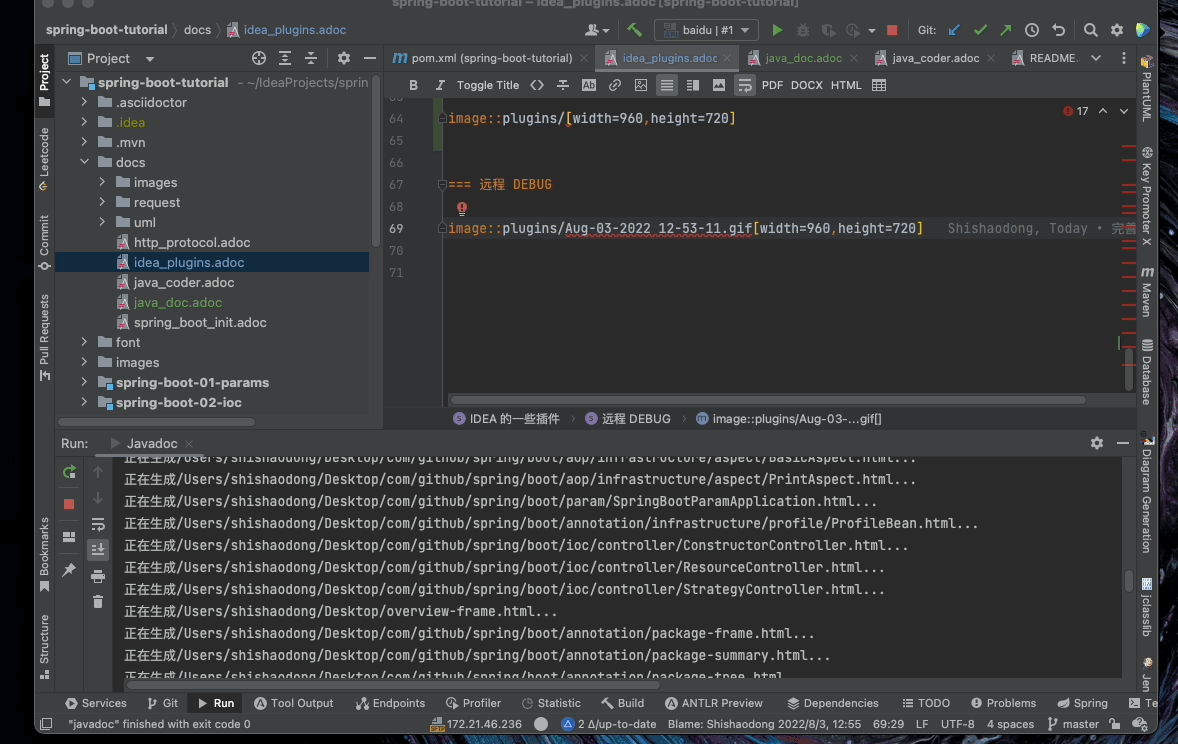
-encoding utf-8 -charset utf-87. 一些参数设置
7.1. 优化层
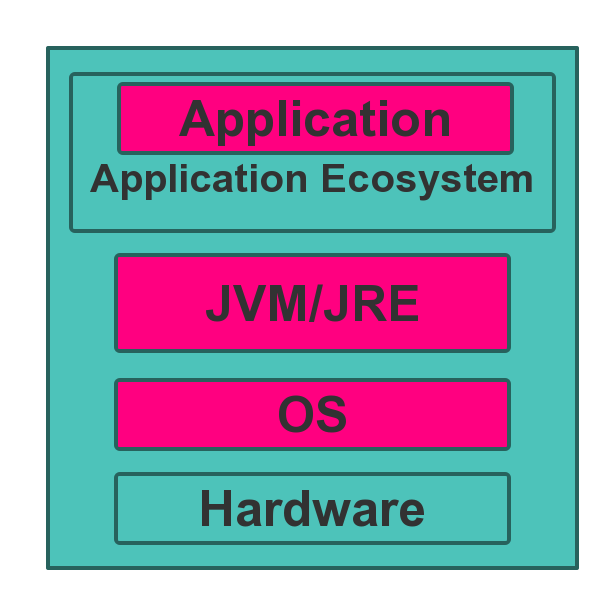
7.2. 硬件
nothing to do 1:2 1:4
7.3. OS
7.3.1. Linux系统最大进程数和最大文件打开数
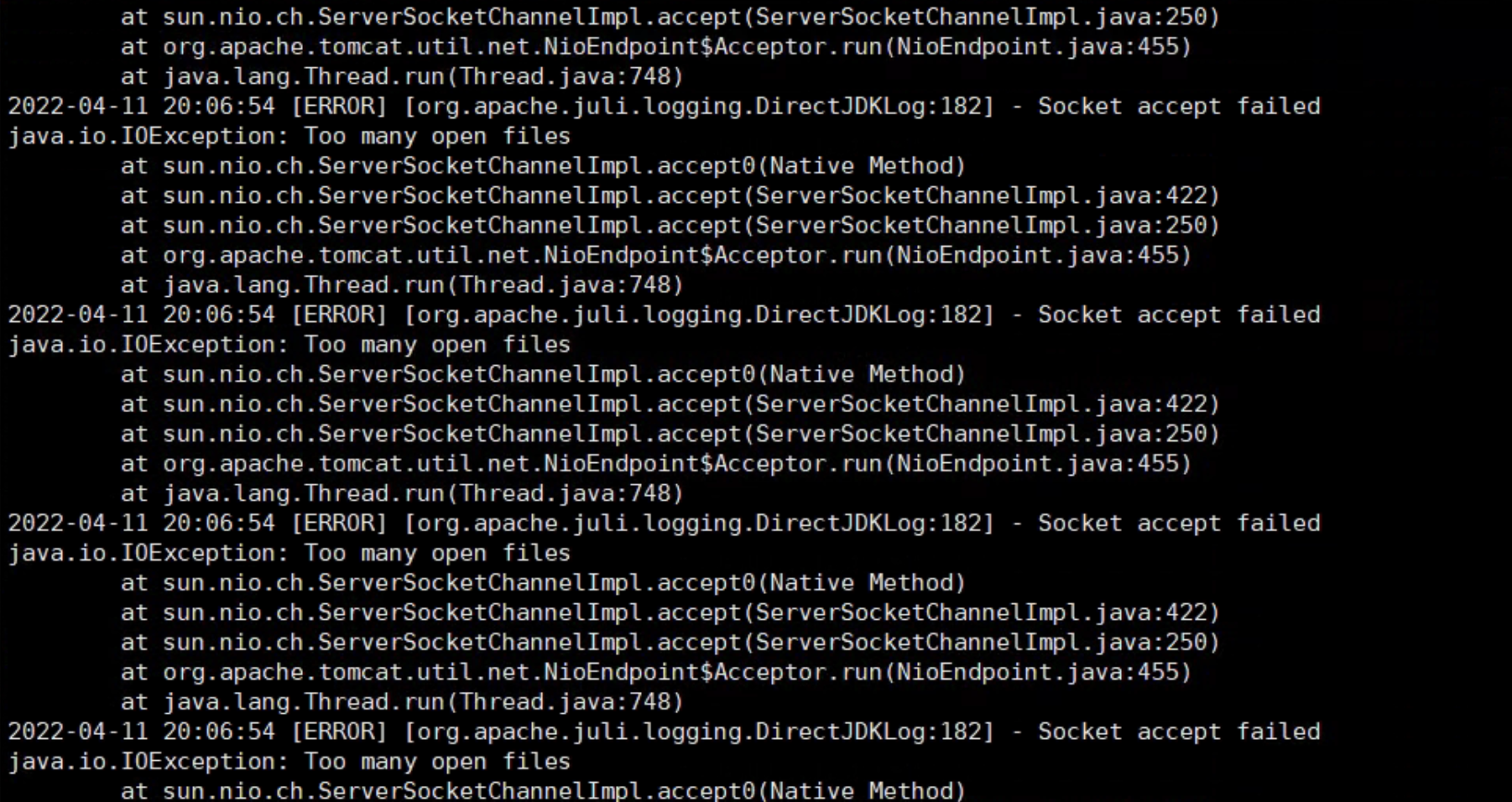
*代表针对所有用户,nproc是代表最大进程数,nofile 是代表最大文件打开数
7.3.2. Swap分区
7.3.3. THP
Centos6开始引入THP,Centos7时默认启用,用来提升内存性能。
transparent_hugepage 是 Linux 内核中的一个特性,用于自动将内存中的小页(通常是 4 KB)合并成大页(通常是 2 MB 或更大)。这个功能有助于提高内存管理的效率和性能,尤其是在处理大量内存的工作负载时。 透明大页的主要作用包括:
-
减少页表项的开销:使用大页可以减少页表项的数量,从而减少页表查找和维护的开销,提高 TLB(Translation Lookaside Buffer,翻译后备缓冲区)的命中率。
-
提高内存访问性能:大页可以减少内存访问时的 TLB 缺失,从而减少访问延迟,提高程序的运行效率。
-
简化内存管理:透明大页是自动管理的,不需要应用程序进行特别的配置或修改,内核会自动尝试将连续的小页合并成大页。
transparent_hugepage 有几种操作模式,可以通过 /sys/kernel/mm/transparent_hugepage/enabled 文件进行配置,常见的模式有:
-
always:总是尝试使用透明大页。
-
madvise:只有在应用程序明确请求(通过 madvise 系统调用)时才使用透明大页。
-
never:从不使用透明大页。
大家可以使用以下命令查看系统是否已经使用 THP:
7.4. JDK
| 配置项 | 类型 | 说明 | 示例 |
|---|---|---|---|
-Xms |
X |
默认是物理内存的1/64 |
|
-Xmx |
X |
默认是物理内存的1/4 |
|
-Xmn |
X |
堆的年轻代区域用于存放新生对象。与其他区域相比,在这个区域执行垃圾回收的频率更高。如果年轻代的内存太小,那么将执行许多次垃圾回收。如果年轻代的内存太大,那么执行完整的垃圾回收可能需要很长时间才能完成。一般建议把年轻代的大小保持在整个堆大小的1/2到1/4之间。 |
Column 4, row 3 |
-Xss |
X |
Column 3, row 4 |
默认JDK1.4中是256K,JDK1.5+中是1M |
-XX:PretenureSizeThreshold |
XX |
对象超过3M时直接晋升到老年代 |
|
-XX:MaxGCPauseMillis |
G1 |
最大停顿时间,默认200 ms |
-XX:MaxGCPauseMillis=180 设置最大停顿时间为 180ms |
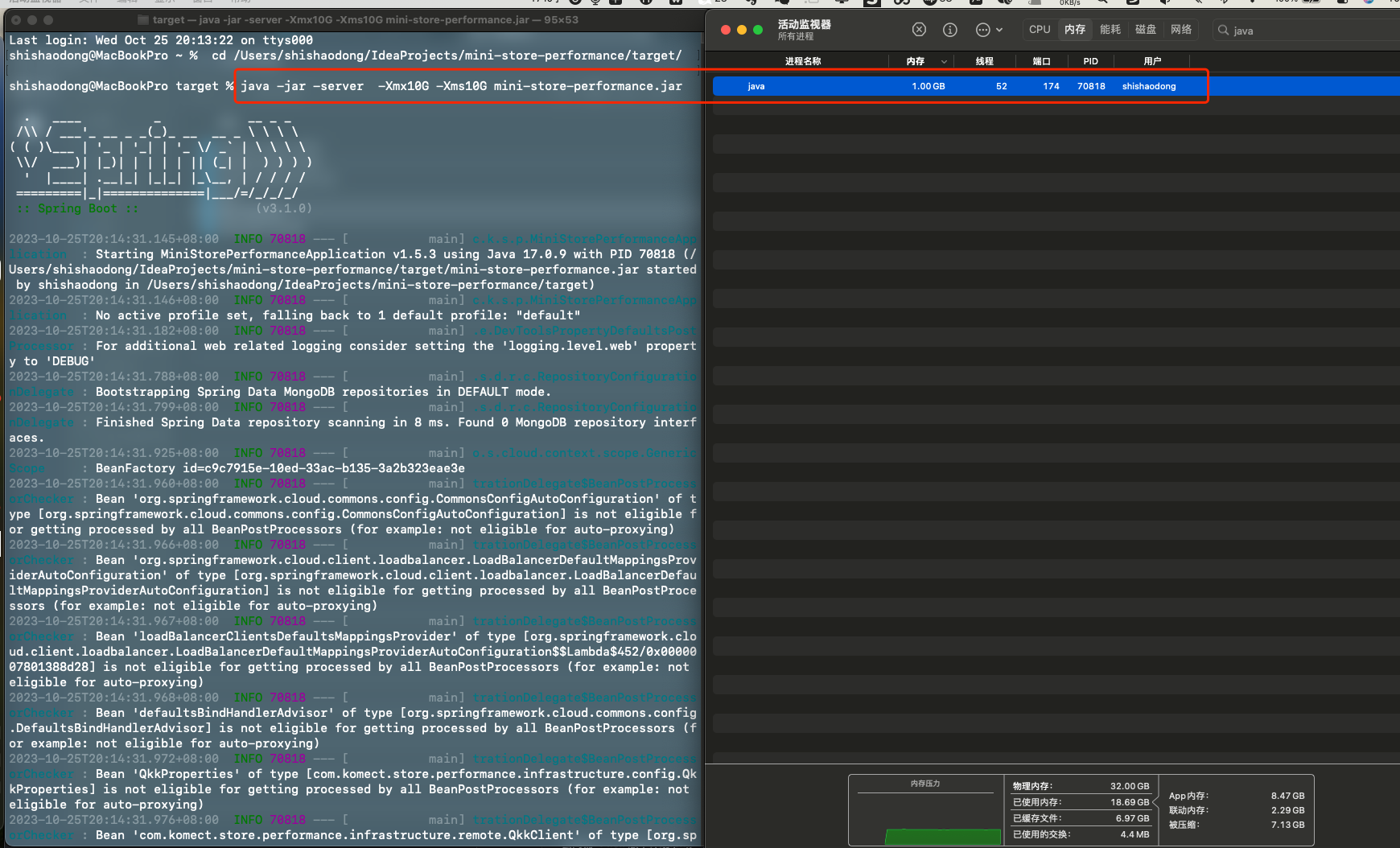
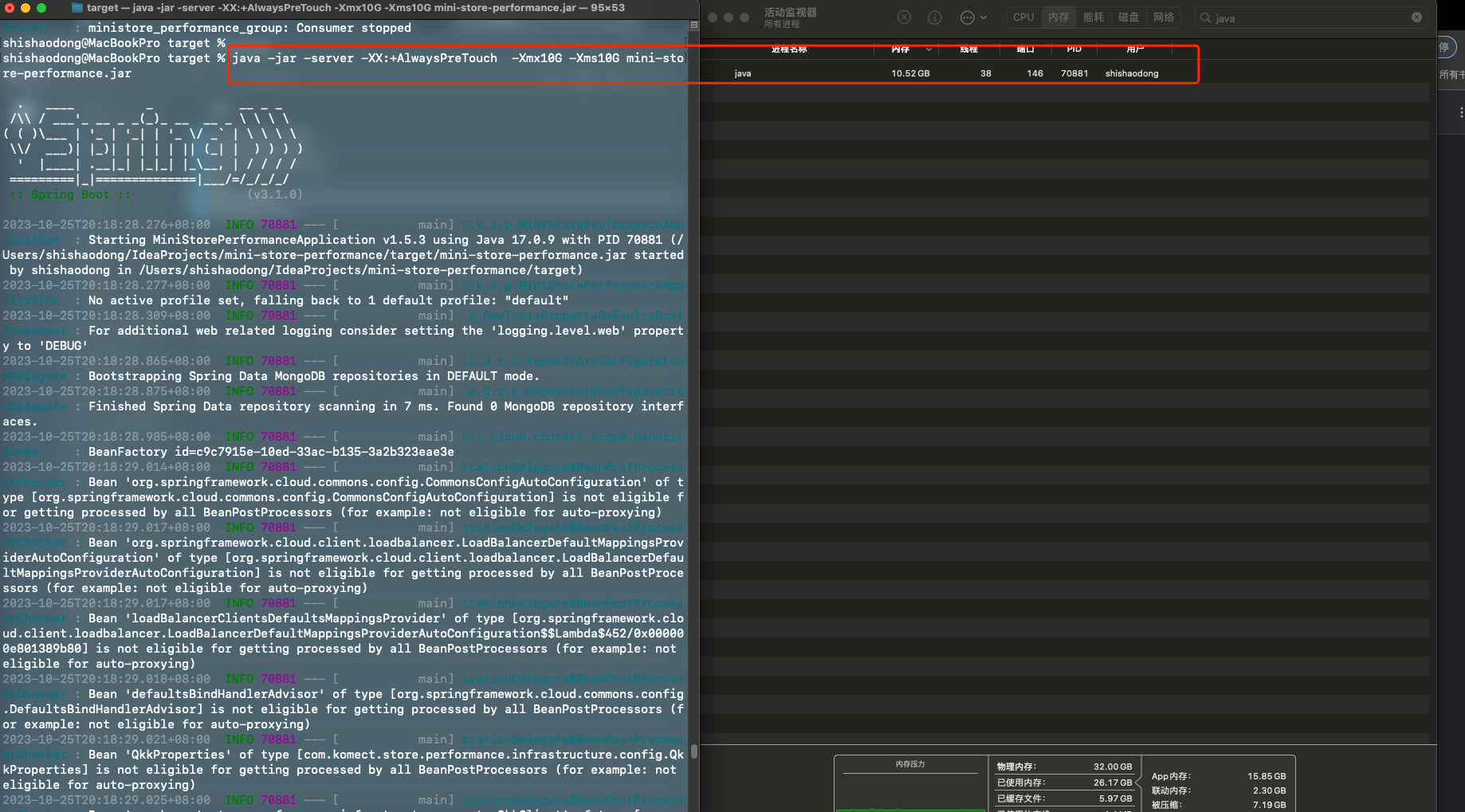
-XX:+AlwaysPreTouch |
预占用内存 |
-XX:+AlwaysPreTouch |
|
-XX:+DoEscapeAnalysis |
表示开启逃逸分析,JDK8是默认开启的 |
-XX:+DoEscapeAnalysis |
7.5. 应用
8. Kubernetes 架构与组件
8.1. 什么是 Kubernetes
Kubernetes(K8s)是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用。它提供了声明式配置和自动化,使得在集群中运行分布式应用变得简单高效。
8.2. Kubernetes 的核心价值
-
容器编排:自动化容器的部署、扩展和管理
-
自我修复:自动重启失败的容器,替换和重新调度容器
-
负载均衡:自动分配网络流量,确保部署的稳定性
-
存储编排:自动挂载选择的存储系统
-
自动部署和回滚:声明式更新,支持自动回滚
-
自动装箱:根据资源需求自动调度容器
-
水平扩展:简单的命令或UI就可以扩展应用
-
自动发现和负载均衡:使用DNS名称或IP地址暴露容器
8.3. Kubernetes 核心组件
8.3.1. Master 节点(控制平面)组件
Master节点运行控制平面组件,负责整个集群的管理和决策。
API Server(kube-apiserver)
作用: - Kubernetes集群的前端,处理所有REST请求 - 与etcd通信,存储和检索集群状态 - 执行认证、授权和准入控制
职责: - 接收用户的kubectl命令或API请求 - 验证请求的合法性 - 将请求的资源对象存储到etcd - 通知其他组件有新的资源对象
Scheduler(kube-scheduler)
作用: - 监听API Server,获取未调度的Pod - 根据资源需求、约束条件和亲和性规则,将Pod分配到合适的Node
调度流程: 1. 获取待调度的Pod列表 2. 过滤不符合条件的Node(预选) 3. 对符合条件的Node进行优先级排序(优选) 4. 选择优先级最高的Node 5. 将Pod绑定到选中的Node
Controller Manager(kube-controller-manager)
作用: - 运行控制器进程,监听资源对象的变化 - 根据资源的期望状态和实际状态,调整集群状态
主要控制器: - Node Controller:监听Node状态,处理Node故障 - Replication Controller:维护Pod副本数量 - Deployment Controller:管理Deployment的更新和回滚 - StatefulSet Controller:管理有状态应用 - DaemonSet Controller:确保每个Node运行一个Pod副本 - Job Controller:管理一次性任务 - Service Controller:管理Service和Endpoint - Namespace Controller:管理命名空间
etcd
作用: - Kubernetes的数据存储后端,存储所有集群数据 - 提供一致性和高可用性的键值存储
存储内容: - 所有Kubernetes对象(Pod、Service、Deployment等) - 集群配置信息 - 应用状态信息
8.3.2. Worker 节点(数据平面)组件
Worker节点运行应用容器,每个Worker节点包含以下组件。
Kubelet
作用: - 运行在每个Worker节点上的代理程序 - 确保Pod中的容器按照PodSpec运行 - 监听API Server的Pod变化,创建、更新或删除Pod
职责: - 从API Server获取Pod定义 - 通过容器运行时(如Docker)启动容器 - 监控容器的健康状态 - 定期向API Server报告节点和Pod的状态 - 执行容器的生命周期钩子(启动、停止等)
Container Runtime(容器运行时)
作用: - 负责下载镜像、运行容器 - 常见的容器运行时:Docker、containerd、CRI-O
职责: - 拉取容器镜像 - 创建和运行容器 - 管理容器的生命周期 - 提供容器的网络和存储接口
kube-proxy
作用: - 运行在每个Worker节点上的网络代理 - 维护网络规则,实现Service的负载均衡
职责: - 监听Service和Endpoint的变化 - 更新iptables或ipvs规则 - 将发往Service的流量转发到对应的Pod - 实现负载均衡和会话保持
8.3.3. 集群级别的组件
DNS(CoreDNS)
作用: - 为集群内的Service提供DNS解析 - 允许Pod通过Service名称访问其他服务
功能: - 为Service创建DNS记录 - 支持服务发现 - 支持跨命名空间的DNS查询
8.4. Kubernetes 对象模型
8.4.1. 常见的Kubernetes资源对象
| 资源对象 | 说明 |
|---|---|
Pod |
Kubernetes最小的可部署单元,包含一个或多个容器 |
Service |
定义一组Pod的访问策略,提供稳定的网络端点 |
Deployment |
声明式更新Pod和ReplicaSet的方式 |
StatefulSet |
管理有状态应用,保证Pod的唯一性和顺序性 |
DaemonSet |
确保集群中的每个Node都运行一个Pod副本 |
Job |
创建一个或多个Pod,并确保指定数量的Pod成功完成 |
CronJob |
按照时间表运行Job |
ConfigMap |
存储非机密的配置数据 |
Secret |
存储敏感数据(密码、令牌等) |
Namespace |
虚拟集群,用于多租户隔离 |
PersistentVolume |
集群中的存储资源 |
PersistentVolumeClaim |
Pod对存储资源的请求 |
8.5. 一次 API 调用的完整过程
8.5.1. 场景:创建一个 Deployment
当用户执行 kubectl create -f deployment.yaml 时,以下是完整的处理流程:

8.5.2. 详细步骤说明
1. 用户提交请求
kubectl create -f deployment.yamlkubectl将YAML文件解析,发送HTTP POST请求到API Server。
8.5.3. 2. API Server 处理请求
认证(Authentication): - 验证请求者的身份 - 支持多种认证方式:证书、令牌、用户名密码等
授权(Authorization): - 检查请求者是否有权限执行此操作 - 支持RBAC(基于角色的访问控制)
准入控制(Admission Control): - 执行自定义的准入策略 - 可以修改或拒绝请求
3. 对象存储到 etcd
API Server将Deployment对象序列化后存储到etcd,确保数据的持久化。
4. Controller Manager 处理
Deployment Controller: - 监听Deployment对象的创建事件 - 根据Deployment的副本数创建对应的ReplicaSet
ReplicaSet Controller: - 监听ReplicaSet对象的创建事件 - 根据副本数创建对应的Pod
5. Scheduler 调度 Pod
预选阶段(Predicate): - 检查Node的资源是否满足Pod的需求 - 检查Node的标签是否满足Pod的亲和性规则 - 过滤出符合条件的Node列表
优选阶段(Priority): - 对符合条件的Node进行评分 - 选择评分最高的Node
绑定阶段(Bind): - 将Pod绑定到选中的Node - 更新Pod的nodeName字段
6. Kubelet 启动容器
监听Pod变化: - Kubelet监听API Server,获取分配给本Node的Pod
创建容器: - 调用容器运行时(如Docker)拉取镜像 - 创建容器并启动 - 配置容器的网络和存储
报告状态: - Kubelet定期向API Server报告Pod的状态 - 更新Pod的phase为Running
7. 返回结果
kubectl收到API Server的响应,显示Deployment创建成功。
8.6. 请求处理的关键流程
8.6.1. Pod 创建的完整流程

8.6.2. Service 流量转发流程
当客户端访问Service时,流量转发的过程:

8.7. Kubernetes 的工作原理总结
8.7.1. 声明式 vs 命令式
声明式(Declarative): - 用户声明期望的状态(如Deployment中的副本数) - Kubernetes自动调整集群状态以匹配期望状态 - 这是Kubernetes推荐的方式
命令式(Imperative): - 用户发出具体的命令(如创建Pod) - 用户需要管理所有的细节
8.7.2. 控制循环(Control Loop)
Kubernetes的核心工作原理是控制循环:
观察(Watch)→ 比较(Diff)→ 调整(Act)→ 观察(Watch)...-
观察:监听资源对象的变化
-
比较:比较期望状态和实际状态
-
调整:执行操作使实际状态匹配期望状态
-
重复:不断循环,确保集群始终处于期望状态
8.7.3. 自我修复机制
-
Pod故障:Kubelet检测到Pod异常,重启容器
-
Node故障:Controller Manager检测到Node不可用,在其他Node上重新创建Pod
-
Deployment更新失败:自动回滚到上一个版本
8.8. 最佳实践
-
使用Deployment而不是直接创建Pod:Deployment提供了自动扩展、更新和回滚功能
-
为Pod设置资源请求和限制:确保Scheduler能够正确调度,防止资源竞争
-
使用健康检查:配置liveness和readiness probe,提高应用的可靠性
-
使用Service暴露应用:提供稳定的网络端点和负载均衡
-
使用ConfigMap和Secret管理配置:将配置与代码分离
-
使用命名空间进行隔离:在多租户环境中实现资源隔离
-
定期备份etcd:保护集群数据
-
监控集群状态:使用Prometheus、Grafana等工具监控集群和应用
9. 接口幂等性
9.1. 什么是幂等性
接口幂等性就是用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。
比如说支付场景,用户购买了商品支付扣款成功,但是返回结果的时候网络异常,此时钱已经扣了,用户再次点击按钮,此时会进行第二次扣款,返回结果成功,用户查询余额发现多扣钱了,流水记录也变成了两条。这就没有保证接口的幂等性。
9.2. 哪些情况需要防止
-
用户多次点击按钮
-
用户页面回退再次提交
-
微服务互相调用:由于网络问题,导致请求失败。feign触发重试机制
-
其他业务情况
9.3. 什么情况下需要幂等
以SQL为例,有些操作是天然幂等的:
幂等操作:
-
SELECT * FROM table WHERE id=?:无论执行多少次都不会改变状态,是天然的幂等 -
UPDATE tab1 SET col1=1 WHERE col2=2:无论执行成功多少次状态都是一致的,也是幂等操作 -
DELETE FROM user WHERE userid=1:多次操作,结果一样,具备幂等性 -
INSERT INTO user(userid, name) VALUES(1, 'a')(userid为唯一主键):重复操作只会插入一条用户数据,具备幂等性
非幂等操作:
-
UPDATE tab1 SET col1=col1+1 WHERE col2=2:每次执行的结果都会发生变化,不是幂等的 -
INSERT INTO user(userid, name) VALUES(1, 'a')(userid不是主键):多次操作,数据都会新增多条,不具备幂等性
9.4. 幂等解决方案
9.4.1. Token 机制
工作流程:
-
服务端提供发送token的接口:在分析业务的时候,哪些业务是存在幂等问题的,就必须在执行业务前,先去获取token,服务器会把token保存到redis中
-
调用业务接口时携带token:一般放在请求头部
-
服务器验证token:判断token是否存在redis中,存在表示第一次请求,然后删除token,继续执行业务
-
拒绝重复请求:如果判断token不存在redis中,就表示是重复操作,直接返回重复标记给client,这样就保证了业务代码,不被重复执行

危险性分析:
先删除token还是后删除token
-
先删除的风险:可能导致业务确实没有执行,重试还带上之前token,由于防重设计导致,请求还是不能执行
-
后删除的风险:可能导致业务处理成功,但是服务闪断,出现超时,没有删除token,别人继续重试,导致业务被执行两次
-
最佳实践:设计为先删除token,如果业务调用失败,就重新获取token再次请求
Token获取、比较和删除必须是原子性
-
如果
redis.get(token)、token.equals、redis.del(token)这些操作不是原子的,可能导致高并发下,都get到同样的数据,判断都成功,继续业务并发执行 -
可以在redis使用lua脚本完成这个操作:
if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end
9.4.2. 各种锁机制
数据库悲观锁
SELECT * FROM xxxx WHERE id=1 FOR UPDATE;-
悲观锁使用时一般伴随事务一起使用,数据锁定时间可能会很长,需要根据实际情况选用
-
注意:id字段一定是主键或者唯一索引,不然可能造成锁表的结果,处理起来会非常麻烦
数据库乐观锁
这种方法适合在更新的场景中:

UPDATE t_goods SET count=count-1, version=version+1
WHERE good_id=2 AND version=1工作原理:
-
根据version版本,在操作库存前先获取当前商品的version版本号,然后操作的时候带上此version号
-
第一次操作库存时,得到version为1,调用库存服务version变成了2
-
但返回给订单服务出现了问题,订单服务又一次发起调用库存服务,当订单服务传入的version还是1
-
再执行上面的sql语句时,就不会执行,因为version已经变为2了,where条件就不成立
-
这样就保证了不管调用几次,只会真正的处理一次
适用场景:乐观锁主要使用于处理读多写少的问题
业务层分布式锁
如果多个机器可能在同一时间同时处理相同的数据,比如多台机器定时任务都拿到了相同数据处理,我们就可以加分布式锁,锁定此数据,处理完成后释放锁。获取到锁的必须先判断这个数据是否被处理过。
9.4.3. 各种唯一约束
数据库唯一约束
插入数据,应该按照唯一索引进行插入,比如订单号,相同的订单就不可能有两条记录插入。我们在数据库层面防止重复。
特点:
-
这个机制是利用了数据库的主键唯一约束的特性,解决了在insert场景时幂等问题
-
但主键的要求不是自增的主键,这样就需要业务生成全局唯一的主键
-
如果是分库分表场景下,路由规则要保证相同请求下,落地在同一个数据库和同一表中,要不然数据库主键约束就不起效果了,因为是不同的数据库和表主键不相关
Redis Set 防重
很多数据需要处理,只能被处理一次。比如我们可以计算数据的MD5将其放入redis的set,每次处理数据,先看这个MD5是否已经存在,存在就不处理。
防重表
使用订单号orderNo做为去重表的唯一索引,把唯一索引插入去重表,再进行业务操作,且他们在同一个事务中。这个保证了重复请求时,因为去重表有唯一约束,导致请求失败,避免了幂等问题。
注意事项:
-
去重表和业务表应该在同一库中,这样就保证了在同一个事务
-
即使业务操作失败了,也会把去重表的数据回滚
-
这个很好的保证了数据一致性
全局请求唯一ID
调用接口时,生成一个唯一id,redis将数据保存到集合中(去重),存在即处理过。
实现方式:
-
可以使用nginx设置每一个请求的唯一id:
proxy_set_header X-Request-Id $request_id;
10. 架构设计
10.1. 架构设计目标
在做架构设计时,一个好的架构应该需要实现以下几个目标:
-
独立于框架:架构不应该依赖某个外部的库或框架,不应该被框架的结构所束缚。
-
独立于UI:前台展示的样式可能会随时发生变化(今天可能是网页、明天可能变成console、后天是独立app),但是底层架构不应该随之而变化。
-
独立于底层数据源:无论今天你用MySQL、Oracle还是MongoDB、CouchDB,甚至使用文件系统,软件架构不应该因为不同的底层数据储存方式而产生巨大改变。
-
独立于外部依赖:无论外部依赖如何变更、升级,业务的核心逻辑不应该随之而大幅变化。
-
可测试:无论外部依赖了什么数据库、硬件、UI或者服务,业务的逻辑应该都能够快速被验证正确性。
这就好像是建筑中的楼宇,一个好的楼宇,无论内部承载了什么人、有什么样的活动、还是外部有什么风雨,一栋楼都应该屹立不倒,而且可以确保它不会倒。但是今天我们在做业务研发时,更多的会去关注一些宏观的架构,比如SOA架构、微服务架构,而忽略了应用内部的架构设计,很容易导致代码逻辑混乱,很难维护,容易产生bug而且很难发现。
软件设计质量最高的时候是第一次设计的那个版本,当第一个版本设计上线以后就开始各种需求变更,这常常又会打乱原有的设计。
软件要做成什么样既不由我们来决定,也不由用户来决定。而是由客观世界决定。
业务细节制定者、领域专家、产品经理、项目经理 、架构师、开发经理、测试经理
10.2. 战略层面
DDD的战略设计主要包括领域/子域、通用语言、限界上下文和架构风格等概念。
-
明确分工:域模型需要明确定义来解决方方面面的问题,而针对这些问题则形成了团队分钟的理解。
-
统一思想:统一项目各方业务、产品、开发对问题的认知,而不是开发和产品统一,业务又和产品统一从而产生分歧。
-
反映变化:需求是不断变化的,因此我们的模型也是在不断的变化的。领域模型则可以真实的反映这些变化。
-
边界分离:领域模型与数据模型分离,用领域模型来界定哪些需求在什么地方实现,保持结构清晰。
10.3. 通用语言
首先它也同样要拥有【简单】的特性,这样才便于理解和传播。
其次,它也要有【通用】、【使用率高】的特性,因为只有在软件开发的过程中,团队范围内所有的参与人员广泛使用,才能准确传递业务规则。
最主要的目的就是减少交流中信息丢失。
11. 参数绑定 ⭐️
11.1. url path 取数据
一般用于 GET/POST/PUT/DELETE 请求
从 URL 中获取参数
HTTP 请求示例
11.2. 通过 body 取数据
可以用于 GET,POST,PUT,DELETE 请求
11.3. 从 header 中获取数据
11.4. 从 cookie 中获取数据
11.5. 从 url 后面获取数据
11.6. 内容协商
同一资源,可以有多种表现形式,比如xml、json等,具体使用哪种表现形式,是可以协商的.
演示请求返回使用 xml 格式
Spring Boot 3.x (Jackson 2.x):
Spring Boot 4 (Jackson 3.x):
请求同样的接口
body 中使用 xml 格式 需要在 header 中添加 Content-Type: application/xml body 添加如下数据
|
提示
|
12. 依赖注入 ⭐️
依赖注入(DI)和控制反转(IOC)基本是一个意思.
DI(依赖注入)最早由 Martin Fowler 提出
今世界软件开发领域最具影响力的五位大师之一。
微服务,DI,领域,敏捷编程等
书籍: 企业应用架构模式, 重构-改善既有代码的设计, UML精粹

依赖注入一共有3种方式
12.1. @Autowired
|
提示
|
12.2. resource 注入
12.3. 构造方法注入
12.4. 依赖查找
场景: 用户登录需要获取短信验证码, 后台需要调用短信接口发送短信.
假设三个运营商接口均只能发送给自己的用户发送短信.
|
缺点
|
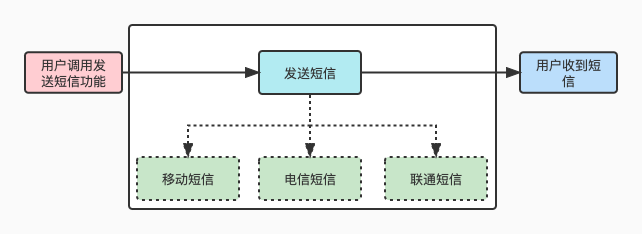
策略模式:该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户。
12.5. 注意事项
-
绝大部分情况下, 注入到 Spring 容器里的 bean 都是单例的;
-
绝大部分情况下, 注入到 Spring 容器里的 bean 都是无状态的;
-
在单例模式下, 如果是有状态的 bean 则要考虑线程安全问题;
13. 面向切面编程 ⭐️
AOP为Aspect Oriented Programming的缩写,意为:面向切面编程,通过预编译方式和运行期间动态代理实现程序功能的统一维护的一种技术(装饰器模式区别).
AOP主要是提供另外一种编程思路,可以把类似的行为抽离出来统一处理.
例如:Aspect(@Aspect), 事务(@Transaction), 异步(@Async), 重试机制(@Retry)
13.1. 基础用法
13.2. 自定义注解
13.3. 匹配特定类型的参数
13.4. 多个指定顺序
13.5. 失效的场景
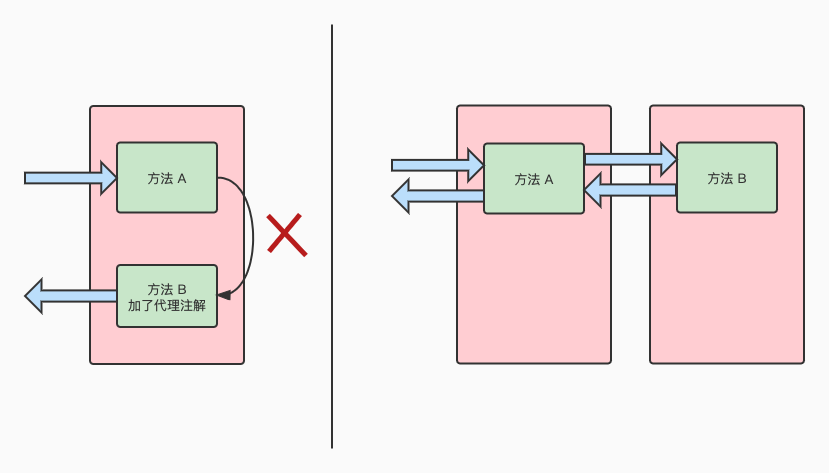
14. 一些常用注解
14.1. @Configuration
使用 @Configuration 注解向容器中注入 Bean
14.2. @Primary @Fallback
有多个实现时,使用 @Primary 优选使用 Bean
@Fallback 注解作用
核心功能 : @Fallback 用于标记一个 后备 Bean,配合 @ConditionalOnSingleCandidate 条件注解使用,解决多实现类场景下的 Bean 注入问题。
14.2.1. @Fallback vs @Primary
| 注解 | 作用 | 优先级 |
|---|---|---|
@Primary |
标记为首选 Bean |
最高优先,优先注入 |
@Fallback |
标记为后备 Bean |
最低优先,只在无其他候选时使用 |
14.3. @ConfigurationProperties
14.4. @Profile
15. Jackson ⭐️
15.1. @JsonFormat
前后端如何传时间
目前 JVM 中一共有两个类型的时间类 LocalDate LocalDateTime 和 Date
LocalDate LocalDateTime 从 Java8 才开始提供
15.2. @JsonProperty
因为某些原因前后端同一个属性命名不一致
15.3. @JsonPropertyOrder
某些场景需要对序列化后的字符串进行排序 如: 对数据进行签名,同样的数据顺序不一样,签名出来的结果
15.4. @Serialization
自定义序列化与反序列化
对输入字段做特殊处理,如不符合JSON格式,字段进行加解密.
15.5. @JsonView
同样的数据返回不同视图
16. Validation
当提供一个接口对外提供服务时,数据校验是必须需要考虑的事情。
很多时候,必须在每个单独的验证框架中实现完全相同的验证。为了避免在每一层重新实现这些验证,许多开发人员会将验证直接捆绑到他们的类中,用复制的验证代码将它们混杂在一起。
这个JSR将为JavaBean验证定义一个元数据模型和API。
JSR303 JSR349 JSR380
JSR是Java Specification Requests的缩写,意思是Java 规范提案
16.1. 基本校验 ⭐️
对某些字段进行参数校验. 如: 名字长度, 年龄, email 格式, 生日等
需要校验的类
用到的地方
JSR 303 校验框架注解类:
-
@NotNull 注解元素必须是非空 • @Null 注解元素必须是空 • @Digits 验证数字构成是否合法 • @Future 验证是否在当前系统时间之后 • @Past 验证是否在当前系统时间之前 • @Max 验证值是否小于等于最大指定整数值 • @Min 验证值是否大于等于最小指定整数值
-
@Pattern 验证字符串是否匹配指定的正则表达式 • @Size 验证元素大小是否在指定范围内 • @DecimalMax 验证值是否小于等于最大指定小数值 • @DecimalMin 验证值是否大于等于最小指定小数值 • @AssertTrue 被注释的元素必须为true • @AssertFalse 被注释的元素必须为false
Hibernate Validator扩展注解类:
-
@Email 被注释的元素必须是电子邮箱地址 • @Length 被注释的字符串的大小必须在指定的范围内 • @NotEmpty 被注释的字符串的必须非空 • @Range 被注释的元素必须在合适的范围内
如何在 IDEA 中查看所有的参数校验注解
16.2. 分组校验 ⭐️
根据需要校验特定字段,应用场景:SpringDataJPA 中 save 方法没有 ID 字段就是保持新的数据,如果有 ID 字段就是跟新数据。 使用方法:首先写一些接口,这里的接口是标记用的,就像 JsonView 一样。
接口 1
接口 2
在要校验的字段上标记注解并指定分组
使用
16.3. 级联校验 ⭐️
所校验的对象是个复杂的结构
16.4. 自定义校验 ⭐️
先定义一个注解
自定义校验逻辑继承 ConstraintValidator
16.5. 交叉校验
交叉校验 方法的入口参数有多个
16.6. 类级别校验 ⭐️
16.7. 手动校验
16.8. controller 校验 ⭐️
16.9. 自定义消息
16.10. 返回值校验
16.11. 指定顺序校验
16.12. 配置文件参数校验
]
16.13. 组合校验 ⭐️
16.14. 快速失败
16.15. 脚本校验
17. Spring Data Redis 教程
本文档介绍 Spring Boot 4.x 中 Spring Data Redis 的使用方法,涵盖常用数据结构、Repository、分布式锁、Pipeline 和 Lua 脚本。
17.1. 依赖配置
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>17.2. 基本配置
# application.properties
spring.data.redis.host=localhost
spring.data.redis.port=6379
spring.data.redis.password=
spring.data.redis.database=0
spring.data.redis.timeout=3000ms
# 连接池配置
spring.data.redis.lettuce.pool.max-active=8
spring.data.redis.lettuce.pool.max-idle=8
spring.data.redis.lettuce.pool.min-idle=0
spring.data.redis.lettuce.pool.max-wait=-1ms17.3. 数据结构操作
Spring Data Redis 通过 RedisTemplate 提供了对各种数据结构的操作支持。
17.3.1. String 操作
@Autowired
private StringRedisTemplate stringRedisTemplate;
public void stringExample() {
// 设置值
stringRedisTemplate.opsForValue().set("key", "value");
// 获取值
String value = stringRedisTemplate.opsForValue().get("key");
// 设置过期时间
stringRedisTemplate.opsForValue().set("key", "value", 60, TimeUnit.SECONDS);
// 只有不存在时才设置(SETNX)
Boolean success = stringRedisTemplate.opsForValue().setIfAbsent("key", "value");
}17.3.2. Hash 操作
public void hashExample() {
// 设置 hash 字段
stringRedisTemplate.opsForHash().put("user:1", "name", "Alice");
stringRedisTemplate.opsForHash().put("user:1", "age", "25");
// 获取 hash 字段
String name = (String) stringRedisTemplate.opsForHash().get("user:1", "name");
// 获取所有字段
Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:1");
// 删除字段
stringRedisTemplate.opsForHash().delete("user:1", "age");
}17.3.3. List 操作
public void listExample() {
// 左侧推入
stringRedisTemplate.opsForList().leftPush("list", "item1");
stringRedisTemplate.opsForList().leftPushAll("list", "item2", "item3");
// 右侧推入
stringRedisTemplate.opsForList().rightPush("list", "item4");
// 获取范围元素
List<String> items = stringRedisTemplate.opsForList().range("list", 0, -1);
// 弹出元素
String item = stringRedisTemplate.opsForList().leftPop("list");
}17.3.4. Set 操作
public void setExample() {
// 添加元素
stringRedisTemplate.opsForSet().add("set", "member1", "member2", "member3");
// 获取所有成员
Set<String> members = stringRedisTemplate.opsForSet().members("set");
// 判断成员是否存在
Boolean isMember = stringRedisTemplate.opsForSet().isMember("set", "member1");
// 集合运算
Set<String> intersection = stringRedisTemplate.opsForSet().intersect("set1", "set2");
Set<String> union = stringRedisTemplate.opsForSet().union("set1", "set2");
Set<String> difference = stringRedisTemplate.opsForSet().difference("set1", "set2");
}17.3.5. ZSet(有序集合)操作
public void zSetExample() {
// 添加成员(分数)
stringRedisTemplate.opsForZSet().add("rank", "Alice", 100.0);
stringRedisTemplate.opsForZSet().add("rank", "Bob", 85.5);
stringRedisTemplate.opsForZSet().add("rank", "Charlie", 95.0);
// 获取范围成员(按分数升序)
Set<String> range = stringRedisTemplate.opsForZSet().range("rank", 0, -1);
// 获取范围成员及分数
Set<ZSetOperations.TypedTuple<String>> rangeWithScores =
stringRedisTemplate.opsForZSet().rangeWithScores("rank", 0, -1);
// 获取指定成员的排名(从0开始)
Long rank = stringRedisTemplate.opsForZSet().rank("rank", "Alice");
// 获取指定成员的分数
Double score = stringRedisTemplate.opsForZSet().score("rank", "Alice");
// 增加分数
stringRedisTemplate.opsForZSet().incrementScore("rank", "Alice", 10.0);
// 按分数范围获取
Set<String> rangeByScore = stringRedisTemplate.opsForZSet()
.rangeByScore("rank", 80.0, 100.0);
}17.3.6. HyperLogLog 操作
HyperLogLog 用于基数统计,适合统计大量不重复元素(如 UV 统计)。
public void hyperLogLogExample() {
// 添加元素
stringRedisTemplate.opsForHyperLogLog().add("uv:20240101", "user1", "user2", "user3");
// 获取基数(不重复元素数量)
Long size = stringRedisTemplate.opsForHyperLogLog().size("uv:20240101");
// 合并多个 HyperLogLog
stringRedisTemplate.opsForHyperLogLog().union("uv:total",
"uv:20240101", "uv:20240102", "uv:20240103");
}17.4. Repository 模式
Spring Data Redis 支持 Repository 模式,将实体映射到 Redis Hash。
17.4.1. 定义实体
import org.springframework.data.annotation.Id;
import org.springframework.data.redis.core.RedisHash;
import lombok.Data;
@Data
@RedisHash(timeToLive = 3600) // 默认过期时间(秒)
public class User {
@Id
private String id;
private String name;
private Integer age;
private String email;
}17.4.2. 定义 Repository
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface UserRepository extends CrudRepository<User, String> {
// 自定义查询方法
Iterable<User> findByName(String name);
}17.4.3. 使用 Repository
@Service
@RequiredArgsConstructor
public class UserService {
private final UserRepository userRepository;
public void userRepositoryExample() {
// 保存用户
User user = new User();
user.setId("user:1");
user.setName("Alice");
user.setAge(25);
user.setEmail("alice@example.com");
userRepository.save(user);
// 查询用户
Optional<User> foundUser = userRepository.findById("user:1");
// 查询所有用户
Iterable<User> allUsers = userRepository.findAll();
// 自定义查询
Iterable<User> usersByName = userRepository.findByName("Alice");
// 删除用户
userRepository.deleteById("user:1");
}
}17.5. SETNX 分布式锁
SETNX(SET if Not eXists)是实现分布式锁的常用方式。
17.5.1. 简单分布式锁
import org.springframework.stereotype.Service;
import lombok.RequiredArgsConstructor;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
@Service
@RequiredArgsConstructor
public class DistributedLockService {
private final StringRedisTemplate stringRedisTemplate;
private static final String LOCK_PREFIX = "lock:";
private static final long LOCK_EXPIRE_TIME = 30; // 秒
/**
* 尝试获取锁
* @param lockKey 锁的键
* @return 锁标识,如果获取失败返回 null
*/
public String tryLock(String lockKey) {
String lockValue = UUID.randomUUID().toString();
Boolean success = stringRedisTemplate.opsForValue()
.setIfAbsent(LOCK_PREFIX + lockKey, lockValue, LOCK_EXPIRE_TIME, TimeUnit.SECONDS);
return success ? lockValue : null;
}
/**
* 释放锁(使用 Lua 脚本确保原子性)
* @param lockKey 锁的键
* @param lockValue 锁标识
*/
public void unlock(String lockKey, String lockValue) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then " +
"return redis.call('del', KEYS[1]) " +
"else return 0 end";
stringRedisTemplate.execute(
new DefaultRedisScript<>(script, Long.class),
Collections.singletonList(LOCK_PREFIX + lockKey),
lockValue
);
}
/**
* 使用锁执行业务
* @param lockKey 锁的键
* @param task 业务逻辑
*/
public void executeWithLock(String lockKey, Runnable task) {
String lockValue = tryLock(lockKey);
if (lockValue != null) {
try {
task.run();
} finally {
unlock(lockKey, lockValue);
}
} else {
throw new RuntimeException("获取锁失败");
}
}
}17.5.2. 使用分布式锁
@RestController
@RequiredArgsConstructor
public class LockController {
private final DistributedLockService lockService;
@PostMapping("/deduct-stock")
public String deductStock() {
lockService.executeWithLock("product:123", () -> {
// 执行扣减库存等需要保证原子性的操作
System.out.println("执行业务逻辑");
});
return "success";
}
}17.6. Pipeline(管道)批量操作
Pipeline 可以在一次网络交互中执行多个命令,大幅提升性能。
import org.springframework.stereotype.Service;
import lombok.RequiredArgsConstructor;
import java.util.List;
@Service
@RequiredArgsConstructor
public class PipelineService {
private final StringRedisTemplate stringRedisTemplate;
public void pipelineExample() {
// 执行多个命令
stringRedisTemplate.executePipelined((RedisCallback<Object>) connection -> {
for (int i = 0; i < 100; i++) {
String key = "item:" + i;
connection.set(key.getBytes(), ("value" + i).getBytes());
}
return null; // Pipeline 必须返回 null
});
// 批量获取
List<Object> results = stringRedisTemplate.executePipelined((RedisCallback<Object>) connection -> {
for (int i = 0; i < 100; i++) {
connection.get(("item:" + i).getBytes());
}
return null;
});
// 处理结果
for (Object result : results) {
System.out.println(result);
}
}
}17.7. Lua 脚本
Lua 脚本可以保证多个命令的原子性执行。
17.7.1. 创建 Lua 脚本文件
# src/main/resources/script/increment_with_limit.lua
local current = tonumber(redis.call('GET', KEYS[1])) or 0
if current < tonumber(ARGV[1]) then
redis.call('SET', KEYS[1], current + 1)
return 1
else
return 0
end17.7.2. 配置 Lua 脚本
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.scripting.support.ResourceScriptSource;
@Configuration
public class RedisScriptConfig {
@Value("classpath:script/increment_with_limit.lua")
private Resource incrementScriptResource;
@Bean
public DefaultRedisScript<Long> incrementWithLimitScript() {
DefaultRedisScript<Long> script = new DefaultRedisScript<>();
script.setScriptSource(new ResourceScriptSource(incrementScriptResource));
script.setResultType(Long.class);
return script;
}
}17.7.3. 使用 Lua 脚本
import org.springframework.stereotype.Service;
import lombok.RequiredArgsConstructor;
import java.util.Collections;
@Service
@RequiredArgsConstructor
public class LuaScriptService {
private final StringRedisTemplate stringRedisTemplate;
private final DefaultRedisScript<Long> incrementWithLimitScript;
public void luaScriptExample() {
// 执行脚本:计数器达到上限前返回 1 并递增,否则返回 0
Long result = stringRedisTemplate.execute(
incrementWithLimitScript,
Collections.singletonList("counter:limit"),
"10" // 上限值
);
if (result == 1) {
System.out.println("递增成功");
} else {
System.out.println("达到上限");
}
}
// 动态脚本(生产环境不推荐)
public void dynamicScriptExample() {
String script = "local current = tonumber(redis.call('get', KEYS[1]) or 0) " +
"redis.call('set', KEYS[1], current + tonumber(ARGV[1])) " +
"return current + tonumber(ARGV[1])";
Long result = stringRedisTemplate.execute(
new DefaultRedisScript<>(script, Long.class),
Collections.singletonList("dynamic:counter"),
"5"
);
}
}17.8. 总结
-
数据结构:String、Hash、List、Set、ZSet、HyperLogLog 覆盖大部分场景
-
Repository:适合将实体直接映射到 Redis,简化 CRUD 操作
-
分布式锁:SETNX + Lua 保证原子性,防止误删锁
-
Pipeline:批量操作减少网络开销,提升性能
-
Lua 脚本:复杂逻辑原子执行,支持自定义扩展
选择合适的方案可以充分发挥 Redis 的性能优势。
18. JPA
为什么?
能做什么? redis mongodb es neo4j
18.1. 注解
| 序号 | 注解 | 说明 | 注释 |
|---|---|---|---|
1 |
@Entity |
标记实体类 |
Column 4, row 1 |
2 |
@Table |
标记表注解 |
Column 4, row 1 |
3 |
@DynamicInsert |
动态插入数据 |
Column 4, row 1 |
4 |
@DynamicUpdate |
动态更新数据 |
Column 4, row 1 |
5 |
@Id |
标记主键 |
Column 4, row 1 |
6 |
@GeneratedValue |
主键生成策略 |
Column 4, row 1 |
7 |
@Column |
表列生成策略 |
Column 4, row 1 |
8 |
@AttributeOverride |
Column 3, row 1 |
Column 4, row 1 |
9 |
@Transient |
Column 3, row 1 |
Column 4, row 1 |
10 |
@UniqueConstraint |
标记唯一索引注解 |
@UniqueConstraint(name = "UK_USERNAME", columnNames = {"username"}) |
11 |
@Index |
标记索引注解 |
@Index(name = "IDX_NOTE", columnList = "note") |
18.2. 转换器
| 注解 | 注解 | 说明 | 注释 |
|---|---|---|---|
13 |
Convert |
标记实体类 |
Column 4, row 1 |
18.3. 领域事件
| 序号 | 注解 | 说明 | 注释 |
|---|---|---|---|
15 |
@DomainEvents |
领域事件 |
Column 4, row 1 |
16 |
@AfterDomainEventPublication |
领域事件回调 |
Column 4, row 1 |
17 |
@TransactionalEventListener |
领域事件监听 |
Column 4, row 1 |
18.4. 投影
在只读场景下,我们不需要查询整个实体,只需要数据库中某些字段吧,这个时候可以使用投影. 使用投影也可以防止修改数据库中的数据.
18.4.1. 数据库查询 interface 方式投影
基本用法,先定义一个 interface
新增一个查询方法,如 <T> Optional<T> findById(long id, Class<T> clz); ;
使用接口方式还支持 SPEL 表达式,
SPEL 支持
18.4.2. 数据库查询 class 方式投影
使用 class 方式进行投影,
注意所有字段均是 private final
|
18.4.3. 数据库查询 record 方式投影
使用 record 方式进行投影,
18.4.4. 请求参数绑定投影
http 接口也支持 interface 投影,方式接收
首先在 interface 上加 @ProjectedPayload 注解, 在对应的方法上加上 @JsonPath 注解
18.5. JPQL
mysql JSON 格式字段
类上加注解
字段上加注解
18.6. 动态查询
18.7. 事务
18.8. one to many
18.9. many to many
18.10. one to one
19. Spring Data MongoDB 教程
19.1. 什么是 Spring Data MongoDB?
Spring Data MongoDB 是 Spring Data 家族中的一个模块,提供了对 MongoDB 数据库的高级支持。它简化了 MongoDB 数据访问层的开发,通过提供 Repository 抽象、MongoTemplate 和声明式查询等功能,使开发者能够更轻松地与 MongoDB 交互,而无需编写复杂的 MongoDB 驱动代码。
19.2. Spring Data MongoDB 的主要作用
-
简化数据访问:通过 Repository 接口自动生成查询方法,减少样板代码
-
灵活的查询:支持声明式查询、方法名查询、
@Query注解查询等多种方式 -
MongoTemplate:提供低级别的 MongoDB 操作接口,支持复杂的查询和更新操作
-
自动映射:自动将 MongoDB 文档映射到 Java 对象,支持嵌套对象和集合
-
索引管理:支持通过注解定义索引,包括单字段索引、复合索引、TTL索引等
-
审计支持:通过
@CreatedDate、@LastModifiedDate等注解自动记录创建和修改时间 -
事务支持:支持 MongoDB 事务(4.0+版本)
19.3. 适用场景
-
文档存储:存储灵活的、非结构化的数据
-
日志系统:存储应用日志、操作日志等时间序列数据
-
内容管理:存储文章、评论等内容数据
-
用户数据:存储用户信息、用户行为数据
-
缓存数据:使用 TTL 索引实现自动过期的缓存
-
分析数据:存储和分析大量的非结构化数据
-
物联网数据:存储传感器数据、设备数据等
19.4. Spring Data MongoDB 的核心特性
-
Repository 接口:继承
MongoRepository自动获得 CRUD 操作 -
方法名查询:通过方法名自动生成查询逻辑
-
@Query 注解:支持自定义 MongoDB 查询语句
-
索引注解:
@Indexed、@CompoundIndex等用于定义索引 -
审计注解:
@CreatedDate、@LastModifiedDate、@Version等 -
文档映射:
@Document、@Field、@TypeAlias等用于映射配置 -
MongoTemplate:提供
update()、query()、aggregate()等操作方法
19.5. 本教程目标
本教程演示如何在 Spring Boot 应用中使用 Spring Data MongoDB 进行数据操作。通过本教程,你将学会:
-
添加和配置 Spring Data MongoDB 依赖
-
定义 MongoDB 文档实体和索引
-
创建 MongoRepository 接口进行 CRUD 操作
-
使用 MongoTemplate 进行复杂查询和更新
-
实现 TTL 索引实现数据自动过期
-
使用审计注解记录创建和修改时间
-
动态集合名称和自动创建集合
19.6. 依赖配置
在 pom.xml 中添加 Spring Data MongoDB 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>19.7. 配置 MongoDB 连接
在 application.properties 中配置 MongoDB 连接信息:
# MongoDB 连接 URI
spring.data.mongodb.uri=mongodb://localhost:27017/test_db
# 或者分别配置
spring.data.mongodb.host=localhost
spring.data.mongodb.port=27017
spring.data.mongodb.database=test_db
spring.data.mongodb.username=user
spring.data.mongodb.password=password19.8. 启用 MongoDB 审计
在启动类中添加 @EnableMongoAuditing 注解启用审计功能:
package cn.zorbus.mongo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.data.mongodb.config.EnableMongoAuditing;
import org.springframework.scheduling.annotation.EnableScheduling;
@EnableScheduling
@EnableMongoAuditing
@SpringBootApplication
public class SpringBootMongoApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBootMongoApplication.class, args);
}
}19.9. 定义 MongoDB 文档实体
19.9.1. 基本文档定义
使用 @Document 注解定义 MongoDB 文档,@Field 注解定义字段映射:
package cn.zorbus.mongo.domain.entity;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
import org.springframework.data.annotation.Id;
import org.springframework.data.annotation.TypeAlias;
import org.springframework.data.mongodb.core.mapping.Document;
import org.springframework.data.mongodb.core.mapping.Field;
@Data
@Builder
@ToString
@NoArgsConstructor
@AllArgsConstructor
@Document(collection = "user_info")
@TypeAlias("UserInfoEntity")
public class UserInfoEntity {
@Id
private String id;
@Field("username")
private String username;
@Field("address")
private String address;
@Field("age")
private Integer age;
}19.9.2. 文档注解详解
| 注解 | 说明 |
|---|---|
|
标记类为 MongoDB 文档, |
|
标记字段为文档的主键 ID |
|
指定字段在 MongoDB 中的名称,支持字段映射 |
|
为文档类型定义别名,用于多态查询 |
|
标记字段不被持久化到数据库 |
|
标记字段为版本号,用于乐观锁 |
19.10. 索引管理
19.10.1. 单字段索引
使用 @Indexed 注解定义单字段索引:
package cn.zorbus.mongo.domain.entity;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.NoArgsConstructor;
import lombok.ToString;
import org.springframework.data.annotation.Id;
import org.springframework.data.annotation.TypeAlias;
import org.springframework.data.mongodb.core.index.Indexed;
import org.springframework.data.mongodb.core.mapping.Document;
import java.time.LocalDateTime;
@Builder
@ToString
@NoArgsConstructor
@AllArgsConstructor
@Document(collection = "auto_create")
@TypeAlias("AutoCreateEntity")
public class AutoCreateEntity {
@Id
private String id;
@Indexed
private LocalDateTime date;
}19.10.2. 复合索引和 TTL 索引
使用 @CompoundIndex 定义复合索引,使用 expireAfterSeconds 定义 TTL 索引:
package cn.zorbus.mongo.domain.entity;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.NoArgsConstructor;
import lombok.ToString;
import org.springframework.data.annotation.CreatedDate;
import org.springframework.data.annotation.Id;
import org.springframework.data.annotation.LastModifiedDate;
import org.springframework.data.annotation.Transient;
import org.springframework.data.annotation.TypeAlias;
import org.springframework.data.annotation.Version;
import org.springframework.data.mongodb.core.index.CompoundIndex;
import org.springframework.data.mongodb.core.index.Indexed;
import org.springframework.data.mongodb.core.mapping.Document;
import org.springframework.data.mongodb.core.mapping.Field;
import java.util.Date;
@Builder
@ToString
@NoArgsConstructor
@AllArgsConstructor
@Document(collection = "data_with_ttl")
@CompoundIndex(name = "index", def = "{'message':1,'field':1}")
@TypeAlias("DataWithTtlEntity")
public class DataWithTtlEntity {
@Id
private String id;
@Indexed
private String name;
private String field;
@Field("desc")
private String message;
/**
* TTL 索引:60 秒后自动删除文档
* 注意:expire 字段必须是 Date 类型
*/
@Indexed(name = "IDX_TTL", expireAfterSeconds = 60)
private Date expire;
@CreatedDate
@Field("created_date")
private Date createdDate;
@LastModifiedDate
@Field("last_modified_date")
private Date lastModifiedDate;
/**
* @Transient 标记的字段不会保存到数据库
*/
@Transient
private Long temp;
/**
* 版本号,用于乐观锁
*/
@Version
private Long version;
}19.11. Repository 操作
19.11.1. 创建 MongoRepository 接口
继承 MongoRepository 接口自动获得 CRUD 操作:
package cn.zorbus.mongo.domain.repository;
import cn.zorbus.mongo.domain.entity.UserInfoEntity;
import org.springframework.data.mongodb.repository.MongoRepository;
import java.util.Optional;
public interface IUserInfoRepository extends MongoRepository<UserInfoEntity, String> {
/**
* 方法名查询:自动生成查询逻辑
* 查询指定用户名的用户,并投影到指定类型
*/
<T> Optional<T> findByUsername(String username, Class<T> clz);
}19.11.2. MongoRepository 常用方法
| 方法 | 说明 |
|---|---|
|
保存或更新单个文档 |
|
保存或更新多个文档 |
|
根据 ID 查询单个文档 |
|
查询所有文档 |
|
分页查询 |
|
删除单个文档 |
|
根据 ID 删除文档 |
|
删除所有文档 |
|
统计文档数量 |
19.12. MongoTemplate 操作
19.12.1. 使用 MongoTemplate 进行复杂操作
MongoTemplate 提供了更灵活的 MongoDB 操作方式,支持复杂的查询和更新:
package cn.zorbus.mongo.application.service;
import cn.zorbus.mongo.domain.entity.UserInfoEntity;
import cn.zorbus.mongo.infrastructure.common.command.UserInfoUpdateCommand;
import lombok.RequiredArgsConstructor;
import org.jetbrains.annotations.NotNull;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.stereotype.Service;
import static org.springframework.data.mongodb.core.query.Criteria.where;
import static org.springframework.data.mongodb.core.query.Query.query;
import static org.springframework.data.mongodb.core.query.Update.update;
@Service
@RequiredArgsConstructor
public class UserInfoService {
private final MongoTemplate template;
/**
* Upsert 操作:如果文档存在则更新,不存在则插入
*/
public void upserting(@NotNull UserInfoUpdateCommand command) {
template.update(UserInfoEntity.class)
.matching(query(where("username").is(command.username())
.and("address").is(command.address())))
.apply(update("age", command.age()))
.upsert();
}
}19.12.2. MongoTemplate 常用操作
| 方法 | 说明 |
|---|---|
|
插入新文档 |
|
保存或更新文档 |
|
开始更新操作,支持链式调用 |
|
执行查询操作 |
|
执行聚合管道操作 |
|
删除匹配的文档 |
|
查询并修改文档 |
19.13. 动态集合名称
19.13.1. 使用 SpEL 动态指定集合名称
可以使用 SpEL 表达式动态指定集合名称,从 Bean 中获取集合名称:
@Document(collection = "#{@auto.getName()}")
@TypeAlias("AutoCreateEntity")
public class AutoCreateEntity {
// ...
}19.13.2. 定义集合名称提供者 Bean
创建一个 Bean 提供集合名称:
@Component("auto")
public class CollectionNameProvider {
public String getName() {
return "auto_create_" + LocalDate.now().format(DateTimeFormatter.ofPattern("yyyyMMdd"));
}
}19.14. 定时任务与集合操作
19.14.1. 定时保存数据
使用 @Scheduled 注解定时执行任务,保存数据到 MongoDB:
package cn.zorbus.mongo.application.task;
import cn.zorbus.mongo.domain.entity.AutoCreateEntity;
import cn.zorbus.mongo.domain.repository.IAutoCreateRepository;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
@Slf4j
@Component
@RequiredArgsConstructor
public class AutoCreateTask {
private final IAutoCreateRepository repository;
/**
* 每毫秒执行一次(实际中应该设置合理的时间间隔)
*/
@Scheduled(fixedRate = 1)
public void task() {
log.info("AutoCreateTask");
repository.save(AutoCreateEntity.builder()
.date(LocalDateTime.now())
.build());
}
}19.15. 最佳实践
-
合理使用索引:为经常查询的字段创建索引,提高查询性能
-
使用 TTL 索引:对于需要自动过期的数据(如日志、临时数据),使用 TTL 索引
-
选择合适的查询方式:简单查询用方法名查询,复杂查询用 MongoTemplate
-
避免大文档:MongoDB 文档大小有限制(16MB),避免存储过大的文档
-
使用投影:只查询需要的字段,减少网络传输
-
批量操作:使用
saveAll()等批量方法提高性能 -
监控集合大小:定期清理过期数据,防止集合过大
-
使用审计注解:自动记录创建和修改时间,便于数据追踪
20. kafka
21. actuator
21.1. 什么是 Actuator?
Spring Boot Actuator 是 Spring Boot 提供的一个强大的监控和管理模块,它通过暴露一系列 HTTP 端点或 JMX 接口,使得开发者和运维人员能够实时监控和管理 Spring Boot 应用程序的运行状态。
21.2. Actuator 的主要作用
-
应用监控:实时查看应用的运行状态、性能指标、内存使用情况等
-
健康检查:通过
/health端点检查应用及其依赖服务(数据库、Redis等)的健康状态 -
应用信息:通过
/info端点获取应用的基本信息(版本、名称等) -
Bean 管理:通过
/beans端点查看 Spring 容器中所有的 Bean 定义 -
环境变量:通过
/env端点查看应用的环境变量和配置属性 -
性能指标:通过
/metrics端点获取应用的性能指标(JVM、HTTP请求等) -
自定义指标:支持自定义健康检查指标和业务指标
21.3. 使用场景
-
生产环境监控:实时监控应用的运行状态,及时发现问题
-
性能分析:分析应用的性能瓶颈,优化系统性能
-
故障排查:快速定位问题,查看应用的详细信息
-
自动化运维:与监控平台(如 Prometheus、ELK)集成,实现自动化监控和告警
-
容器编排:在 Kubernetes 等容器平台中用于健康检查和就绪检查
21.4. 常见的 Actuator 端点
| 端点 | 说明 |
|---|---|
|
应用健康状态检查,包括数据库、Redis等依赖服务 |
|
应用信息,如版本、名称、联系方式等 |
|
显示应用中所有的 Spring Bean |
|
显示应用的环境变量和配置属性 |
|
显示应用的性能指标 |
|
显示线程信息 |
|
显示和修改日志级别 |
|
显示最近的 HTTP 请求 |
21.5. 本教程目标
本教程将介绍如何在 Spring Boot 应用中配置和使用 Actuator 模块,实现应用监控与管理功能。通过本教程,你将学会:
-
添加和配置 Actuator 依赖
-
配置 Actuator 端点的暴露和访问权限
-
自定义健康检查指标
-
访问和使用 Actuator 提供的各种端点
21.6. 添加依赖
首先,在项目的 [pom.xml] 中添加以下依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>21.7. 配置 Actuator
在 [application.properties] 文件中对 Actuator 进行基本配置:
server.port=8808
management.server.port=6789
management.endpoints.enabled-by-default=true
management.endpoints.web.exposure.include=health,info,beans,env
management.endpoints.web.base-path=/actuator
management.endpoint.health.show-details=always
management.health.redis.enabled=true21.8. 自定义健康检查指标
创建一个自定义的健康检查类 [ActuatorHealthIndicator](file:///Users/zorbus/IdeaProjects/spring-boot-tutorial/spring-boot-13-actuator/src/main/java/com/github/actuator/config/ActuatorHealthIndicator.java#L18-L25) 实现 HealthIndicator 接口:
package com.github.actuator.config;
import org.springframework.boot.actuate.health.Health;
import org.springframework.boot.actuate.health.HealthIndicator;
import org.springframework.stereotype.Component;
@Component("ActHealth")
public class ActuatorHealthIndicator implements HealthIndicator {
@Override
public Health health() {
return Health.up().withDetail("up", "spring boot up").build();
}
}21.9. 提供 RESTful 接口
创建一个简单的控制器类 [ActuatorController] 来提供测试接口:
package com.github.actuator.config;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ActuatorController {
@GetMapping("/hello")
public String getHello() {
return "hello";
}
}21.10. 启动类
Spring Boot 的启动类 [SpringBootActuatorApplication] 如下所示:
package com.github.actuator;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SpringBootActuatorApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBootActuatorApplication.class, args);
}
}21.11. 访问 Actuator 端点
启动应用程序后,可以通过以下地址访问 Actuator 提供的各种端点信息:
-
应用主服务运行在 http://localhost:8808/
-
Actuator 管理端点位于 http://localhost:6789/actuator
-
健康检查端点:http://localhost:6789/actuator/health
-
应用信息端点:http://localhost:6789/actuator/info
-
Bean 信息端点:http://localhost:6789/actuator/beans
-
环境信息端点:http://localhost:6789/actuator/env
22. Docker 部署
22.1. SpringBoot3.2
目前 SpringBoot 支持直接打包成 docker 镜像
22.1.1. 打镜像说明
22.1.2. 打包成镜像命令
22.1.3. POM 修改
k8s/buildpack/bellsoft-liberica/buildpack.toml
k8s/buildpack/spring-boot/buildpack.toml
k8s/buildpack/syft/buildpack.toml
23. MapStruct 教程
23.1. 什么是 MapStruct?
MapStruct 是一个 Java 注解处理器,用于生成类型安全的 Bean 映射代码。它可以自动创建两个 Java Bean 之间的映射关系,避免手动编写样板代码,提高开发效率并减少错误。MapStruct 在编译时生成映射器实现,性能优异,是处理对象转换的最佳实践工具。
23.2. MapStruct 的主要作用
-
自动映射:自动映射同名字段,减少手动编写转换代码
-
类型安全:编译时检查,避免运行时错误
-
高性能:生成的映射代码是编译后的 Java 代码,性能与手写代码相同
-
灵活配置:支持自定义映射规则、表达式、日期格式化等
-
集合支持:自动处理
List、Set、Map等集合类型的映射 -
对象更新:支持在现有对象上更新属性,而不仅仅是创建新对象
23.3. 适用场景
-
DTO 与实体类转换:在分层架构中,经常需要在
DTO(Data Transfer Object) 和Entity实体之间进行转换 -
API 数据传输:将内部对象转换为对外暴露的 API 对象,保护内部结构
-
领域对象转换:在不同的业务领域或模块间传递数据时的对象映射
-
避免重复代码:替代手动编写大量的
getter/setter转换代码,提升代码质量 -
微服务通信:在微服务间传递数据时进行对象转换
23.4. MapStruct 的主要特性
-
字段映射:自动映射同名字段
-
自定义映射:使用
@Mapping注解指定不同名字段的映射关系 -
表达式映射:使用
expression属性执行 Java 表达式 -
命名转换器:使用
@Named注解创建可复用的转换方法 -
更新映射:使用
@MappingTarget更新现有对象而非创建新对象 -
集合映射:自动映射
List、Set等集合类型 -
后处理:使用
@AfterMapping在映射完成后执行额外逻辑 -
前置处理:使用
@BeforeMapping在映射开始前执行逻辑
23.5. 本教程目标
本教程将介绍如何在 Spring Boot 项目中集成和使用 MapStruct 进行对象映射。通过本教程,你将学会:
-
添加和配置 MapStruct 依赖
-
创建 MapStruct Mapper 接口
-
使用各种映射注解(
@Mapping、@Named、@AfterMapping等) -
处理集合类型的映射
-
编写单元测试验证映射功能
23.6. MapStruct 注解详解
23.6.1. 核心注解
1. 映射器定义注解
@Mapper-
标记接口或抽象类为
MapStruct映射器,是最重要的注解常用属性:
-
componentModel: 指定生成的映射器如何被注入(Spring、`CDI`等) -
nullValueCheckStrategy: 空值检查策略 -
nullValuePropertyMappingStrategy: 空值属性映射策略 -
unmappedSourcePolicy/unmappedTargetPolicy: 未映射属性的处理策略
-
2. 属性映射注解
@Mapping-
定义单个属性的映射规则
常用属性:
-
target: 目标属性名称 -
source: 源属性名称 -
expression: 使用 Java 表达式进行映射 -
qualifiedByName: 指定使用的命名转换器 -
dateFormat: 日期格式化 -
numberFormat: 数字格式化
-
@MappingTarget-
标记参数为目标对象,用于更新现有对象而不是创建新对象
@Named-
为转换方法命名,可在
@Mapping中通过qualifiedByName引用
3. 生命周期注解
@BeforeMapping-
在映射开始前执行的方法
@AfterMapping-
在映射完成后执行的方法
4. 集合和特殊类型注解
@IterableMapping-
定义集合类型(List、Set等)的映射规则
@MapMapping-
定义
Map类型的映射规则 @BeanMapping-
定义
Bean级别的映射规则
5. 配置继承注解
@InheritConfiguration-
继承其他方法的映射配置
@InheritInverseConfiguration-
继承其他方法的反向映射配置
23.6.2. 添加依赖
首先在 [pom.xml] 中添加 MapStruct 相关依赖和编译插件配置:
23.6.3. 定义实体类
创建源对象 [AccountCommand]:
创建目标对象 [Account]:
23.6.4. 创建 Mapper 接口
创建 [AccountMapper] 映射接口:
23.6.5. 编写测试类
创建 [AccountMapperTest] 测试类验证映射功能:
23.6.6. 启动类
Spring Boot 启动类:
24. Spring Retry 教程
24.1. 什么是 Spring Retry?
Spring Retry 是 Spring Framework 提供的一个轻量级的重试框架,用于在应用程序中实现自动重试机制。它通过注解或编程方式,使得在方法执行失败时能够自动进行重试,而无需手动编写复杂的重试逻辑。Spring Retry 支持灵活的重试策略、退避策略和恢复机制。
24.2. Spring Retry 的主要作用
-
自动重试:在方法执行失败时自动进行重试,提高系统可靠性
-
灵活的重试策略:支持固定次数重试、指数退避等多种重试策略
-
异常处理:精细化控制哪些异常需要重试,哪些不需要
-
恢复机制:通过
@Recover注解定义重试失败后的恢复逻辑 -
监听器支持:通过
RetryListener监听重试过程中的各个阶段 -
简化开发:使用注解方式简化重试逻辑的实现
24.3. 适用场景
-
网络请求重试:调用远程 API 或 HTTP 服务时,网络波动导致的临时失败
-
数据库操作重试:数据库连接超时、死锁等临时性错误
-
消息队列重试:消息发送失败、消费失败的重试
-
分布式系统:在分布式环境中处理临时性故障
-
第三方服务调用:调用外部服务时的容错处理
-
缓存预热:缓存加载失败时的重试
24.4. Spring Retry 的核心特性
-
声明式重试:使用
@Retryable注解标记需要重试的方法 -
多种重试策略:支持简单重试策略、复合重试策略等
-
退避策略:支持固定延迟、线性退避、指数退避等
-
恢复回调:通过
@Recover或RecoveryCallback处理重试失败 -
重试监听:通过
RetryListener监听重试的各个阶段 -
编程式重试:使用
RetryTemplate进行编程式重试
24.5. 本教程目标
本教程演示如何在 Spring Boot 应用中使用 Spring Retry 实现重试机制。通过本教程,你将学会:
-
添加和配置 Spring Retry 依赖
-
使用
@Retryable注解实现声明式重试 -
使用
@Recover注解定义恢复逻辑 -
配置重试策略和退避策略
-
使用
RetryTemplate进行编程式重试 -
实现自定义
RetryListener监听重试过程
24.6. 依赖配置
在 pom.xml 中添加 Spring Retry 依赖:
<dependency>
<groupId>org.springframework.retry</groupId>
<artifactId>spring-retry</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
</dependency>24.7. 启用 Spring Retry
在启动类中添加 @EnableRetry 注解:
package cn.zorbus.retry;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.retry.annotation.EnableRetry;
@EnableRetry
@SpringBootApplication
public class SpringBootRetryApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBootRetryApplication.class, args);
}
}24.8. 声明式重试(注解方式)
24.8.1. 基本使用
使用 @Retryable 注解标记需要重试的方法,使用 @Recover 注解定义恢复逻辑:
package cn.zorbus.retry.service.impl;
import cn.zorbus.retry.service.IRetryService;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.retry.annotation.Backoff;
import org.springframework.retry.annotation.Recover;
import org.springframework.retry.annotation.Retryable;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
@Slf4j
@Service
public class RetryServiceImpl implements IRetryService {
private static final String REMOTE_URL = "http://www.shishaodong.com/";
@Resource
private RestTemplate restTemplate;
/**
* @Retryable 注解参数说明:
* - value: 指定需要重试的异常类型
* - maxAttempts: 最大重试次数(包括首次调用)
* - backoff: 退避策略配置
* - listeners: 重试监听器
*/
@Retryable(
value = Exception.class,
maxAttempts = 2,
backoff = @Backoff(delay = 1000L, multiplier = 1.5),
listeners = {"RemoteRemoteListener"}
)
@Override
public String retry(String id) {
log.info("进入了 retry 方法 id:" + id);
return restTemplate.getForObject(REMOTE_URL + id, String.class);
}
/**
* @Recover 注解用于定义重试失败后的恢复逻辑
* 方法参数必须包含异常对象,其他参数应与 @Retryable 方法一致
*/
@Recover
@Override
public String recover(Exception e, String id) {
log.warn("进入了 recover 方法:" + id);
return "recover";
}
}24.8.2. @Retryable 注解参数详解
| 参数 | 说明 |
|---|---|
|
指定需要重试的异常类型数组,默认为空数组 |
|
最大重试次数,包括首次调用,默认为 3 |
|
重试延迟时间(毫秒),默认为 1000 |
|
退避乘数,用于指数退避策略,默认为 0(不使用) |
|
退避策略配置,使用 |
|
重试监听器 Bean 名称数组 |
|
恢复方法名称 |
24.9. 编程式重试(RetryTemplate)
24.9.1. 配置 RetryTemplate
创建配置类定义 RetryTemplate Bean:
package cn.zorbus.retry.config.retry;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.retry.RetryPolicy;
import org.springframework.retry.backoff.ExponentialBackOffPolicy;
import org.springframework.retry.backoff.ThreadWaitSleeper;
import org.springframework.retry.policy.SimpleRetryPolicy;
import org.springframework.retry.support.RetryTemplate;
@Configuration
public class ConfigRetryTemplate {
@Bean
public RetryTemplate retryTemplate() {
RetryTemplate template = new RetryTemplate();
// 重试策略:最多重试 3 次
RetryPolicy retryPolicy = new SimpleRetryPolicy(3);
template.setRetryPolicy(retryPolicy);
// 退避策略:指数退避
ExponentialBackOffPolicy backOffPolicy = new ExponentialBackOffPolicy();
backOffPolicy.setInitialInterval(100); // 初始延迟 100ms
backOffPolicy.setMaxInterval(3000); // 最大延迟 3000ms
backOffPolicy.setMultiplier(2); // 每次延迟翻倍
backOffPolicy.setSleeper(new ThreadWaitSleeper());
template.setBackOffPolicy(backOffPolicy);
return template;
}
}24.9.2. 使用 RetryTemplate
在控制器中注入并使用 RetryTemplate:
package cn.zorbus.retry.controller.impl;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.retry.RecoveryCallback;
import org.springframework.retry.RetryContext;
import org.springframework.retry.support.RetryTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Date;
@Slf4j
@RestController
public class ManualRetryController {
@Resource
private RetryTemplate retryTemplate;
int a = 0;
/**
* 基本的重试使用:只指定重试逻辑
*/
@GetMapping("/manual")
public String get() {
return retryTemplate.execute(context -> getString());
}
/**
* 带恢复回调的重试:重试失败后执行恢复逻辑
*/
@GetMapping("/manual2")
public String get2() {
return retryTemplate.execute(context -> getString(), getRecoveryCallback());
}
private String getString() {
System.out.println(new Date());
return (1 / a) + ""; // 会抛出 ArithmeticException
}
/**
* 恢复回调:在重试失败后执行
*/
private RecoveryCallback<String> getRecoveryCallback() {
return new RecoveryCallback<String>() {
@Override
public String recover(RetryContext retryContext) {
return "ERROR";
}
};
}
}24.10. 重试监听器
24.10.1. 实现 RetryListener
创建自定义重试监听器监听重试过程:
package cn.zorbus.retry.config.retry.listener;
import lombok.extern.slf4j.Slf4j;
import org.springframework.retry.RetryCallback;
import org.springframework.retry.RetryContext;
import org.springframework.retry.RetryListener;
import org.springframework.stereotype.Component;
@Slf4j
@Component("RemoteRemoteListener")
public class RemoteRemoteListener implements RetryListener {
/**
* 重试开始前调用
*/
@Override
public <T, E extends Throwable> boolean open(RetryContext context, RetryCallback<T, E> callback) {
log.info("重试开始");
return true;
}
/**
* 重试结束后调用
*/
@Override
public <T, E extends Throwable> void close(RetryContext context, RetryCallback<T, E> callback, Throwable throwable) {
log.info("重试结束");
}
/**
* 重试过程中发生错误时调用
*/
@Override
public <T, E extends Throwable> void onError(RetryContext context, RetryCallback<T, E> callback, Throwable throwable) {
log.warn("重试出错: {}", throwable.getMessage());
}
}24.11. 重试策略详解
24.11.1. 常见的重试策略
| 策略 | 说明 |
|---|---|
|
简单重试策略,指定最大重试次数 |
|
基于超时时间的重试策略 |
|
断路器模式的重试策略,达到阈值后停止重试 |
|
组合多个重试策略 |
24.11.2. 常见的退避策略
| 策略 | 说明 |
|---|---|
|
无退避,立即重试 |
|
固定延迟退避 |
|
线性退避,延迟时间线性增长 |
|
指数退避,延迟时间指数增长 |
|
指数随机退避 |
24.12. 最佳实践
-
选择合适的异常:只对临时性异常进行重试,不要重试业务异常
-
设置合理的重试次数:避免过多重试导致系统负担
-
使用退避策略:避免重试风暴,给系统恢复时间
-
实现恢复逻辑:重试失败后提供有意义的恢复方案
-
监听重试过程:通过监听器记录日志,便于问题排查
-
避免重试死循环:确保重试最终会停止
-
考虑幂等性:重试的操作应该是幂等的,避免重复执行的副作用
25. permission
25.1. 认证与授权-授权
25.1.1. 添加注释
25.1.2. 放行所有的 URL、get 和 post 请求
25.1.3. 添加校验的类
25.1.4. 使用注解进行校验
26. Spring Boot Modulith 教程
这是一个基于 Spring Modulith 构建的模块化应用程序示例,演示了事件驱动架构、模块间通信和事件管理等功能。
26.1. 核心组件
26.1.1. RequestCommand 事件对象
这是一个简单的记录类(record),用于表示请求命令事件,包含 [id] 和 [name] 两个属性。
26.1.2. 事件发布控制器
该控制器负责发布 RequestCommand 事件。当访问 /modulith 路径时,会创建并发布一个 RequestCommand 事件。
26.1.3. 事件监听处理器
事件监听器使用 @ApplicationModuleListener 注解监听事件,并配置了重试机制: - 最大重试次数:2次 - 重试间隔:初始500ms,每次增加1.5倍延迟 - 当重试失败后,调用 [recover] 方法进行恢复处理
26.1.4. 未完成事件管理控制器
该控制器提供了对未完成事件的管理功能: - /incomplete/events:获取所有未完成事件的 UUID 列表 - /incomplete/incomplete-events:获取所有未完成事件的详细信息 - /incomplete/event/pub/{uuidString}:重新发布指定 UUID 的事件 - /incomplete/event/{uuidString}:标记指定 UUID 的事件为已完成
26.2. 工作流程
-
用户访问
/modulith接口触发事件发布 -
[ModulithController] 创建
RequestCommand事件并发布 -
[ModulithEventHandlerService] 监听到事件并尝试处理
-
由于处理逻辑抛出异常,触发重试机制
-
重试失败后调用恢复方法
-
未完成的事件被持久化,可通过
/incomplete/**接口查看和管理
26.3. 主要特性
-
模块化设计:使用 Spring Modulith 实现清晰的模块边界
-
事件驱动:通过应用事件实现松耦合的模块间通信
-
容错机制:集成 Spring Retry 提供自动重试和恢复功能
-
事件追踪:提供对未完成事件的监控和管理能力
27. 单元测试-jpa
28. 单元测试-kafka
29. 单元测试-rest
30. Testcontainers 完整教程
30.1. 什么是 Testcontainers?
Testcontainers 是一个开源的 Java 库,它提供了轻量级的、一次性的 Docker 容器,用于在测试中运行真实的服务(如数据库、消息队列、缓存等)。它允许开发者在隔离的容器环境中执行集成测试,无需手动配置和管理外部服务。
30.2. Testcontainers 的主要作用
-
真实环境测试:在真实的服务容器中运行测试,而不是使用 Mock 或内存数据库
-
自动化管理:自动拉取、启动、停止和清理容器,无需手动操作
-
环境隔离:每次测试都在干净的容器环境中运行,避免测试间的相互影响
-
多服务支持:支持 MySQL、PostgreSQL、Redis、MongoDB、RabbitMQ 等多种服务
-
简化配置:通过
@DynamicPropertySource动态注入容器连接信息到 Spring 配置 -
提高测试质量:发现在真实环境中才能暴露的问题
30.3. 适用场景
-
数据库集成测试:测试 JPA Repository、SQL 查询等数据访问层
-
缓存测试:测试 Redis、Memcached 等缓存操作
-
消息队列测试:测试 RabbitMQ、Kafka 等消息系统
-
微服务集成测试:在容器中运行依赖的微服务进行端到端测试
-
CI/CD 流程:在持续集成环境中运行可靠的集成测试
-
本地开发测试:开发人员在本地快速验证功能
30.4. Testcontainers 的核心特性
-
声明式定义:通过注解和代码声明所需的容器
-
动态端口映射:自动处理容器端口到主机端口的映射
-
生命周期管理:自动管理容器的启动和停止
-
多容器编排:支持同时运行多个相关的容器
-
日志捕获:可以捕获容器日志用于调试
-
自定义容器:支持自定义 Docker 镜像和容器配置
30.5. 本教程目标
本教程演示如何在 Spring Boot 应用中使用 Testcontainers 进行集成测试。通过本教程,你将学会:
-
添加和配置 Testcontainers 依赖
-
创建基础容器配置类管理 MySQL 和 Redis 容器
-
使用
@DynamicPropertySource动态配置 Spring 属性 -
编写 MySQL 数据库集成测试
-
编写 Redis 缓存集成测试
-
理解容器生命周期管理
30.6. 先决条件
-
Java 17+
-
Docker(运行容器必需)
-
Maven
30.7. 依赖配置
在 [pom.xml] 中添加以下依赖:
30.8. 实现详解
30.8.1. 基础测试配置
创建基础配置类 [MiddlewareConfig] 来管理容器:
此配置的关键特性:
- 使用 @SpringBootTest 加载完整应用上下文
- 将容器定义为静态字段以便在所有测试方法间共享
- 使用 @DynamicPropertySource 动态配置 Spring 属性
- 通过 @BeforeAll 和 @AfterAll 管理容器生命周期
30.8.2. 实体和仓库定义
定义实体类和数据访问接口:
30.8.3. MySQL 集成测试
创建继承基础配置的测试类:
30.8.4. Redis 集成测试
同样地,测试 Redis 操作:
30.9. 工作原理
-
容器初始化:测试启动时,Testcontainers 自动执行:
-
如果本地不存在所需 Docker 镜像则自动拉取
-
启动配置好的容器
-
暴露端口并提供连接详情
-
-
属性注入:
@DynamicPropertySource方法动态配置 Spring 属性:-
数据库连接 URL、用户名和密码
-
Redis 主机和端口信息
-
-
测试执行:测试在真实服务容器中运行,提供准确的集成测试环境
-
清理工作:测试完成后,容器会自动停止和移除
30.10. 最佳实践
-
基础配置类:在 [MiddlewareConfig]中集中管理容器
-
资源共享:使用静态容器在所有测试方法间共享资源
-
动态属性:运行时配置 Spring 属性
-
生命周期管理:正确启动/停止容器
-
测试顺序:必要时控制测试执行顺序
这种方法确保测试在真实服务环境中运行,同时保持隔离性和可重现性。
31. SpringBoot 虚拟机部署
这里以打出的包名为 spring.jar,运行的用户为 apprun 为例, 以下所有的文件均需apprun有权限
31.1. 开发在pom中作如下配置
31.2. 打包命令
将 java 包上传到服务器,在jar包同级目录中创建 spring.conf 文件,并填写如下配置; -Xmx和-Xms可以根据服务器的内存大小修改; RUN_ARGS 中 location 后面路径可以根据需要改变
创建Java命令连接(Optional,非必须)
在 /etc/systemd/system 目录下创建服务 spring.service
修改权限
重载服务信息
启动服务
停止服务
重启服务
开启开机启动
查看系统进程
查看启动日志(报错)
注意如果启动失败得话需要查看所有文件是否有apprun用户权限